H100 vs A100: Comparing Two Powerhouse GPUs

When it comes to high-performance computing (HPC), the NVIDIA H100 is among the best of the best GPUs on the market. Its predecessor, the NVIDIA A100, is also a very impressive GPU in its own right. From enterprise to exascale, these GPUs are enabling groundbreaking advancements in everything from AI research to complex scientific simulations.
Today we're taking a look at how the H100 and A100 compare with each other. Depending on your use case, one or the other might be better suited for your needs and preferences. So let's dive in!
Introduction to the NVIDIA H100 and A100
As mentioned, the H100 GPU is the successor to the A100. It was specifically optimized for machine learning and designed to deliver an "order-of-magnitude performance leap for large-scale AI and HPC" over the A100, with "substantial improvements in architectural efficiency."
Based on the innovative Hopper architecture, the H100 can speed up large language models (LLMs) by 30X over the A100, according to NVIDIA. It features fourth-gen Tensor Cores and – unlike the A100 – a dedicated Transformer Engine to solve trillion-parameter language models.
Whether it's used in smaller enterprise systems or massive, unified GPU clusters, the H100 delivers efficient scalability thanks to its combination of fourth-gen NVLink (with 900 GB/s of GPU-to-GPU interconnect), NDR Quantum-2 InfiniBand networking (speeding up communication by every GPU across nodes), and PCIe Gen5. With superior FP64 and FP8 performance, the H100 is ideal for next-gen AI workloads.
The A100 GPU is known for its versatility, however. Built on the Ampere architecture, it was groundbreaking when released in 2020, providing up to 20X higher performance over the prior NVIDIA Volta generation. It can efficiently scale up or be partitioned using Multi-Instance GPU (MIG) into seven isolated GPU instances, just like the H100, which is ideal for shifting workload demands.
In short, the A100 excels in both training and inference tasks, and while it may not offer the sheer power of the H100, its robust FP64 performance makes it a great fit for scientific simulations and data analytics.
Key Differences: H100 vs. A100
The H100 has an updated chip design and various other factors that distinguish it from the A100. The following are a few that are important to consider:
Memory Bandwidth
The A100 has a memory bandwidth of about 2 TB/s, which is plenty for most use cases; however, the H100 offers an impressive 3.35 TB/s, making it ideal for workloads where data transfer bottlenecks may occur.
CUDA Cores and Tensor Cores
A higher number of CUDA and Tensor Cores means a GPU can perform more parallel computations simultaneously. With 14,592 CUDA Cores and 456 Tensor Cores, the H100 outperforms the A100’s 6,912 CUDA Cores and 432 Tensor Cores, delivering superior performance in applications that can leverage increased parallelism.
Confidential Computing
The H100's Hopper architecture introduced NVIDIA's new confidential computing environment. It protects data-in-use by performing computation in a trusted execution environment (TEE) that is both hardware-based and attested. This means you essentially have absolute security for use cases where security, privacy, and regulatory compliance are paramount.
Tensor Memory Accelerator (TMA)
Another feature of the H100's Hopper architecture is the TMA unit, which can transfer large blocks of data efficiently between global memory and shared memory. It supports asynchronous copies between thread blocks in a cluster as well, optimizing data movement and memory management for tensor operations. Ultimately, this enhances the efficiency and speed of large-scale AI and deep learning tasks.
MIG Capability
The Multi-Instance GPU (MIG) feature is present in both the H100 and A100, providing flexible workload management so you can run multiple LLMs in parallel, for instance. The H100's MIG capability is more robust, however, with better resource allocation and more memory and compute power to split.
Performance Benchmarks
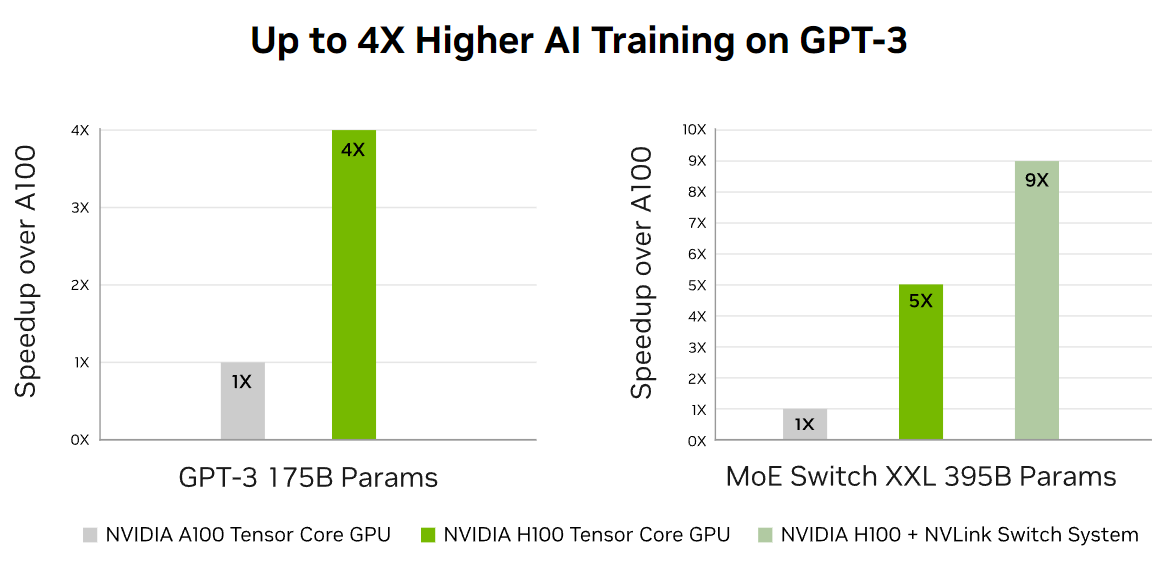
According to NVIDIA's own benchmarks, the H100 offers up to 30X better inference performance than the A100. In another test where the A100 and H100 were used in clusters to train two large language models (LLMs), the H100 demonstrated remarkable speed improvements. The H100's new NVLink Switch System provided an even bigger boost, enabling the H100 cluster to train the models up to nine times faster than the A100 cluster:
Choosing the Right GPU
So what does all this mean for you? The best GPU for your needs will depend on numerous factors. Here's a quick outline of the various features and specs of the NVIDIA A100 and H100:
| Feature | A100 | H100 |
|---|---|---|
| GPU Architecture | Ampere | Hopper |
| GPU Memory | 40 or 80 GB HBM2e | 80 MB HBM3 |
| GPU Memory Bandwidth | 1.6 to 2 TB/s | 3.35 TB/s |
| CUDA Cores | 6912 | 14,592 |
| FP64 TFLOPS | 9.7 | 33.5 |
| FP32 TFLOPS | 19.6 | 67 |
| TF32 Tensor Core Flops* | 156 | 312 | 378 | 756 |
| FP16 Tensor Core Flops* | 312 | 624 | 756 | 1513 |
| FP8 Tensor Core TFLOPS | N/A | 3958 |
| Peak INT8 TOPS* | 624 | 1248 | 3958 |
| Media Engine | 0 NVENC 5 NVDEC 5 NVJPEG | 0 NVENC 7 NVDEC 7 NVJPEG |
| L2 Cache | 40 MB | 50 MB |
| Power | Up to 400 W | Up to 700 W |
| Form Factor | SXM4 - 8-way HGX | SXM5 - 8-way HGX |
| Interconnect | PCIe 4.0 x16 | PCIe 5.0 x16 |
*Without and with structured sparsity.
Use Cases
When it comes to use cases, you may want to consider some general guidelines.
The A100 is well suited for:
- Versatile AI workloads including training and inference.
- Applications needing a balance of performance and cost-efficiency.
- Scenarios where ultra-high precision isn't the priority.
The H100 is ideal for:
- Cutting-edge AI training, large-scale simulations, and other HPC workloads.
- Environments where computational speed and memory bandwidth are critical.
- Future-proofing investments in AI infrastructure.
When deciding between the A100 and H100, consider your specific workload requirements. If you need top-tier double-precision performance and superior memory bandwidth, or you're dealing with next-gen HPC at datacenter scale and trillion-parameter AI, the H100 is the clear winner. For a more versatile and cost-effective solution that still delivers powerful AI performance, the A100 is a solid choice.
At Vast.ai, we understand the importance of finding the right GPU for your needs as well as your budget. Our cloud GPU rental marketplace offers a variety of machines at the lowest prices possible, saving you 5-6X on GPU compute. Whether you prefer on-demand pricing or interruptible instances through spot auction-based pricing, we've got you covered.
We invite you to discover what Vast can do for you and accelerate your projects with the right GPU today!


