Comparing NVIDIA L40 vs. L40s – and More

With all of the GPU options, finding the one that's right for your needs is challenging. Whether you're into high-end cloud gaming, training AI models, or even outfitting a university lab or data center, understanding the nuances between different models is key.
Today, we’re focusing on two powerful GPUs from NVIDIA: the L40 and L40S. While they may not have received as much attention as some of the company's other offerings, they certainly deserve a closer look! These two GPUs, built on the Ada Lovelace architecture, pack a punch in performance and capabilities.
But how do they stack up against each other? What about compared to other GPUs? And more importantly, which one should you choose for your specific project needs?
The Basics: NVIDIA L40 vs. L40S
The L40S is essentially an upgrade to the L40 – as well as a close relative to the RTX 4090 gaming graphics card.
Initially designed for data center graphics and simulation tasks, the L40 is the engine of NVIDIA Omniverse. It's a powerhouse for extended (XR) and virtual reality (VR) applications, design collaboration, and digital twins, thanks to its advanced RTX and AI capabilities. It enables accelerated ray-traced and path-traced rendering, delivers physically accurate simulations, and generates highly realistic 3D synthetic data for the most demanding Omniverse workloads.
Compared to the previous generation, the L40 GPU delivers 5X higher inference performance for compute-intensive AI workloads – so it can generate high-quality images and immersive visual content lightning fast. It's perfectly suited for image generative AI applications. If that's all you need, then the L40 might be an ideal option for you.
However, the L40S can do all of this and more. It was developed to meet the surging demand for GPUs that can handle the intense computational requirements of machine learning training and inference.
NVIDIA describes the L40S as "the most powerful universal GPU," offering "breakthrough multi-workload performance." Here's a quick snapshot of its performance in a couple of areas:
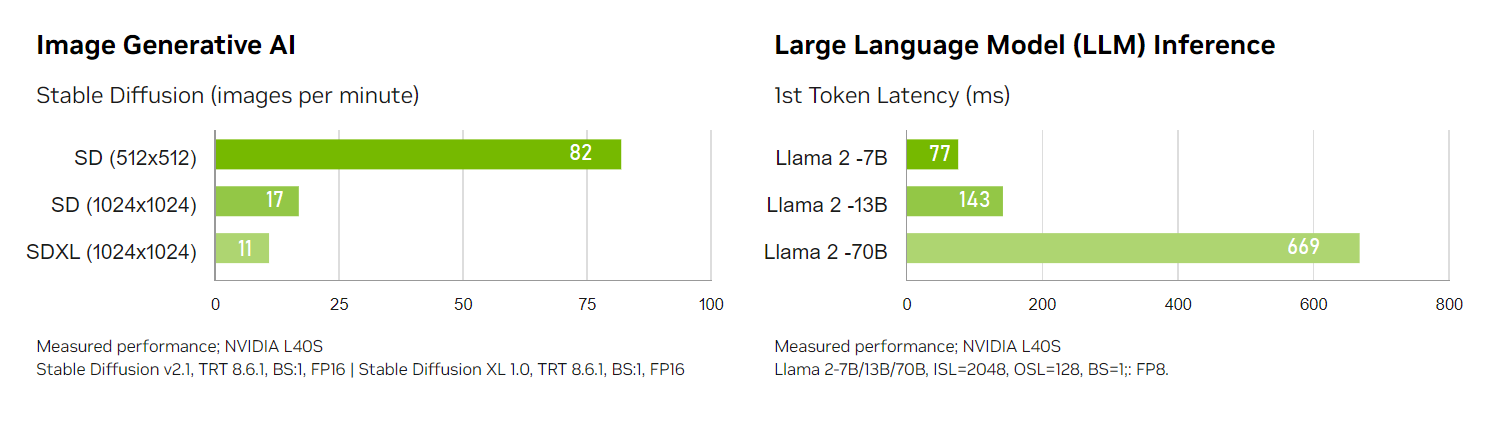
After its release in late 2023, the L40S achieved popularity due to the lack of availability of the NVIDIA A100 and H100 Tensor Core GPUs. There was a massive chip shortage and backlogged shipments, forcing many buyers to turn to other options – like the L40S. Since the L40S can not only be used for the same workloads as the L40 but can also power AI training and inference at a high level like the A100 and H100, it was a logical alternative.
The L40S, A100, and H100 GPUs are therefore in a unique position to be compared with each other. Let's take a look!
L40S vs. A100 vs. H100: Specs and Performance
Each of the three GPUs brings its own strengths to the table. The table below compares various features and specs between them.
| Feature | A100 | L40S | H100 | |------------------------|---------------|----------------|---------------| | GPU Architecture | Ampere | Ada Lovelace | Hopper | | GPU Memory | 40 or 80 GB HBM2e | 48 GB GDDR6 | 80 MB HBM3 | | GPU Memory Bandwidth | 1.6 to 2 TB/s | 864 GB/s | 3.35 TB/s | | CUDA Cores | 6912 | 18,176 | 14,592 | | FP64 TFLOPS | 9.7 | N/A | 33.5 | | FP32 TFLOPS | 19.6 | 91.6 | 67 | | TF32 Tensor Core Flops | 156 | 312 | 183 | 366 | 378 | 756 | | FP16 Tensor Core Flops | 312 | 624 | 362 | 733 | 756 | 1513 | | FP8 Tensor Core TFLOPS | N/A | 1466 | 3958 | | Peak INT8 TOPS | 624 | 1248 | 733 | 1466 | 3958 | | Media Engine | 0 NVENC 5 NVDEC 5 NVJPEG | 0 NVENC 5 NVDEC 5 NVJPEG | 0 NVENC 7 NVDEC 7 NVJPEG | | L2 Cache | 40 MB | 96 MB | 50 MB | | Power | Up to 400 W | Up to 350 W | Up to 700 W | | Form Factor | SXM4 - 8-way HGX | Dual Slot Width | SXM5 - 8-way HGX | | Interconnect | PCIe 4.0 x16 | PCIe 4.0 x16 | PCIe 5.0 x16 |
*Without and with structured sparsity.
As shown, there are some clear differences in performance when it comes to FP64 (double-precision), FP32 (single-precision), and FP16 (half-precision) computations.
For instance, the L40S does not natively support FP64. This means that it may not perform as well as the A100 and H100 in applications that require high precision. The H100 in particular, with its notably superior FP64 performance, is generally preferred for the most demanding tasks.
In terms of FP32 and FP16 Tensor Core performance, the L40S outperforms the A100 40GB and can hold its own against the H100. However, in memory-intensive machine learning scenarios, the L40S's lower memory bandwidth may counterbalance its performance compared to both the A100 80GB and H100.
Still, the L40S can really shine next to the A100 in certain situations. According to NVIDIA, when it comes to complex AI workloads involving billions of parameters and multiple data modalities, including text and video, the L40S can achieve up to 1.2 times the generative AI inference performance and up to 1.7 times the training performance of the A100.
Another point in the L40S's favor? While it may not be able to beat the H100 on certain metrics, it's definitely more flexible. The higher-performance H100 can't be used as an Omniverse server and doesn't support graphics, whereas the L40S can be and does.
The Bottom Line
The NVIDIA L40 excels in powering image generative AI applications and Omniverse workloads. You may not need it for much else, and if that's the case, the L40 would probably serve you well.
On the other hand, the NVIDIA L40S nicely balances versatility as well as performance. The following are some reasons you might choose it for your next project:
- You have multi-modal workloads – You'll achieve remarkable efficiency with the L40S, enabling you to run HPC simulations, train AI models, and render images using the same computing infrastructure. Plus, video output is built in.
- You need compute power fast in a familiar form factor – The L40S is designed for rapid deployment within existing systems, offering powerful performance without requiring extensive reconfiguration. Its Dual Slot PCIe form factor ensures compatibility with a wide range of setups.
- Your workloads don't require extreme precision or maximum speed – Without the math performance (FLOPS), high-bandwidth memory, and NVLINK of the H100, the L40S's inference and training performance for smaller models is nonetheless perfectly suitable in most cases.
- You prioritize cost-effectiveness – The L40S provides an excellent price-to-performance ratio, particularly for enterprises and research institutions that need robust AI capabilities without breaking the budget.
For many of us, cost is a major factor in GPU decision-making. At Vast.ai, our mission is to democratize AI and bring massive compute power, at an affordable price, to anyone who needs it. You don't have to make a huge hardware investment upfront.
Our cloud GPU rental marketplace offers the lowest prices possible, enabling you to access top-tier machines at any time – and save 5-6X on GPU compute. We offer low-cost on-demand pricing as well as interruptible instances through spot auction-based pricing to bring you even more savings.
Come explore what Vast can do for you and accelerate your projects today!


