Serving Online Inference with vLLM API on Vast.ai

Serving Online Inference with vLLM on Vast.ai
Background
vLLM is an open source framework for Large Language model inference. It specifically focuses on throughput for serving and batch workloads. This is important for building apps for multiple users and at scale.
vLLM provides an OpenAI compatible server, which means that you can integrate it into chatbots, and other applications
As companies build out their AI products, they often hit roadblocks like rate limits and cost for using these models. With vLLM on Vast, you can run your own models in the form factor you need, but with much more affordable compute. As inference grows in demand with agents and complicated workflows, vLLM on Vast shines for performance and affordability where you need it the most.
This guide will show you how to setup vLLM to serve an LLM on Vast. We reference a notebook that you can use here
Setup and Querying
First, we setup our environment and vast api key
pip install --upgrade vastai
Once you create your account, you can go here to find your API Key.
vastai set api-key <Your-API-Key-Here>
For serving an LLM, we're looking for a machine that has a static IP address, ports available to host on, plus a single modern GPU with decent RAM since we're going to serve a single small model. vLLM also requires Cuda version 12.4 or higher, so we will filter for that as well. We will query the vast API to get a list of these types of machines.
vastai search offers 'compute_cap > 800 gpu_ram > 20 num_gpus = 1 static_ip=true direct_port_count > 1 cuda_vers >= 12.4'
Deploying the Image:
The easiest way to deploy this instance is to use the command line. Copy and Paste a specific instance id you choose from the list above into instance-id below.
vastai create instance <instance-id> --image vllm/vllm-openai:latest --env '-p 8000:8000' --disk 40 --args --model stabilityai/stablelm-2-zephyr-1_6b
Connecting and Testing:
To connect to your instance, we'll first need to get the IP address and port number. Once your instance is done setting up, you should see something like this:

Click on the highlighted button to see the IP address and correct port for our requests.
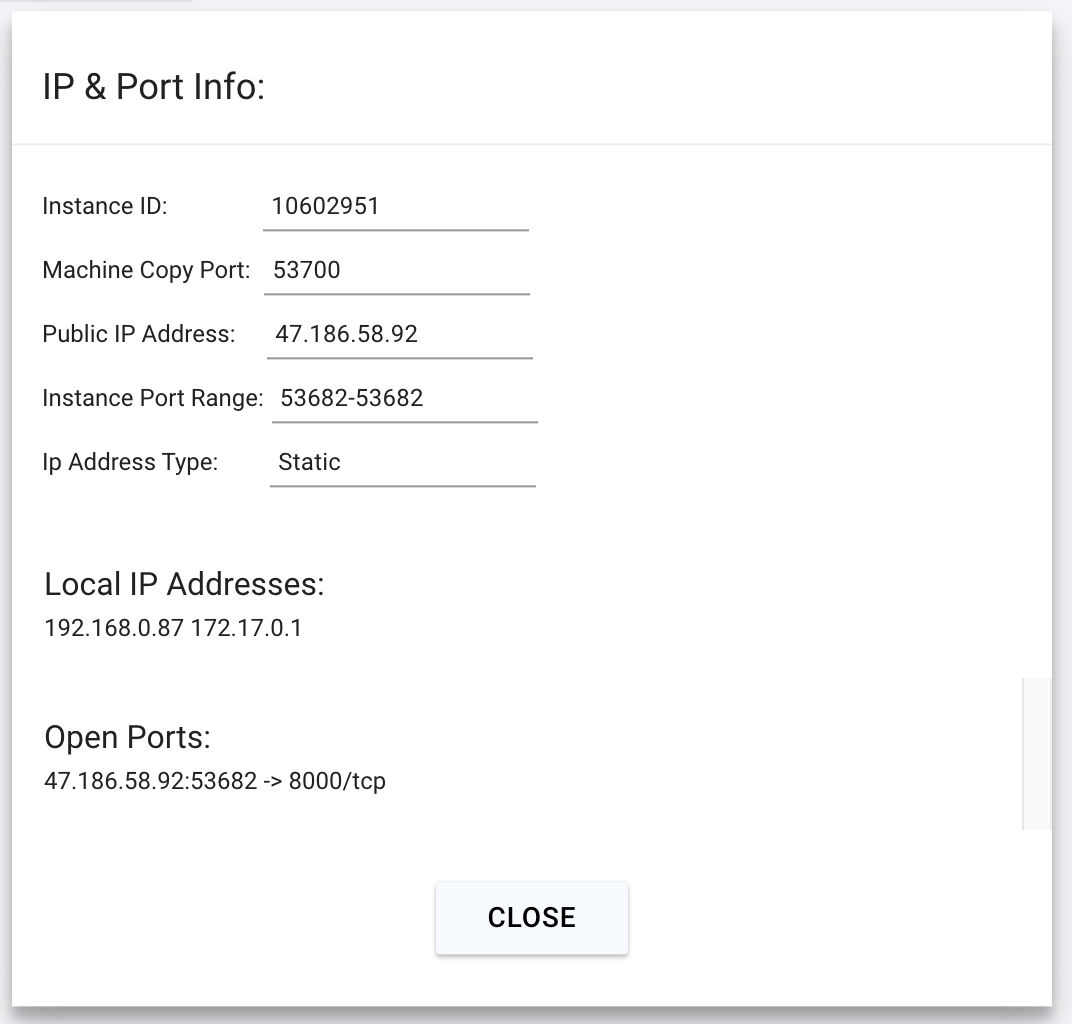
We will copy over the IP address and the port into the cell below.
# This request assumes you haven't changed the model. If you did, fill it in the "model" value in the payload json below
curl -X POST http://<IP-Address>:<Port>/v1/completions -H "Content-Type: application/json" -d '{"model" : "stabilityai/stablelm-2-zephyr-1_6b", "prompt": "Hello, how are you?", "max_tokens": 50}'
You will see a response from your model in the output. Your model is up and running on Vast!
In the notebook, we include ways to call this model with requests or OpenAI
Advanced Usage: Serving a Quantized Llama-3-70b Model:
Now that we've spun up a model on vLLM, we can get into more complicated deployments. We'll work on serving this specific quantized Llama-3 70B model.
With this quantized model, we can easilly serve this model on on 4 4090 GPU's.
What is different this time around:
- The model string - we need to use the new model id.
- We're going to use 4 GPU's instead of just 1.
- We need to provision much more space on our system to be able to download the full set of weights. 100 GB in this case should be fine.
- We need to set up tensor parallelism inside vLLM to split up the model across these 4 gpus.
- We need to let vLLM know that this is a quantized model
First, we will search for instances that match our needs
vastai search offers 'compute_cap >= 800 gpu_ram >= 24 num_gpus = 4 static_ip=true direct_port_count > 1 cuda_vers >= 12.4'
In our instance creation, we will increase our disk usage to 100GB.
Then, we will tell vllm to: 1. use the specific model, 2. split across 4 GPU's, and 3. Let it know that it is in fact a quantized model.
vastai create instance <Instance-ID> --image vllm/vllm-openai:latest --env '-p 8000:8000' --disk 100 --args --model casperhansen/llama-3-70b-instruct-awq --tensor-parallel-size 4 --quantization awq
Other things to look out for with other configurations:
If you are downloading a model that needs authentication from the huggingface hub, passing -e HF_token=<Your-Read-Only-Token> within vast's --env variable string should help.
Sometimes the full context of a model can't be used given the space allocated for vLLM on the GPU + the models size. In those cases, you might want to increase --gpu-memory-utilization, or decrease the max-model-len. Increasing --gpu-memory-utilization does come with CUDA OutOfMemory Issues that can be hard to predict ahead of time.
We won't need either of these for this specific model and GPU configuration.
Testing:
Copy the IP address from your instance once it is ready, and then we can use the following code to call it. Note that while your server might have ports ready, the model might not have downloaded yet as it is much larger this time. You can check the status of this via the logs to see when it has started serving.
import requests
headers = {
'Content-Type': 'application/json',
}
json_data = {
'model': 'casperhansen/llama-3-70b-instruct-awq',
'prompt': 'Hello, how are you?',
'max_tokens': 50,
}
response = requests.post('http://<Instance-IP-Address>:<Port>/v1/completions', headers=headers, json=json_data)
print(response.content)
Or use Open AI:
pip install openai
from openai import OpenAI
# Modify OpenAI's API key and API base to use vLLM's's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://<Instance-IP-Address>:<Port>/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
completion = client.completions.create(model="casperhansen/llama-3-70b-instruct-awq",
prompt="Hello, how are you?",
max_tokens=50)
print("Completion result:", completion)
Conclusions
Model inference is expensive, and leveraging more affordable compute/models makes a huge difference for engineering teams in terms of margins, and shipping velocity.
Using vLLM on Vast is perfect for this, pairing Vast's access to affordable compute with the simplicity and State of the Art throughput of the vLLM backend.
vLLM is a great beginning to building Generative AI Apps. We will continue to explore using this tool more with Vast in future posts.
Llama-3 is already ready to go on Vast to start experimenting and building!


