Examining the NVIDIA GH200
.png&w=1920&q=90)
NVIDIA's highly anticipated next-generation GH200 Grace Hopper Superchip platform is finally available. Perfectly suited for the era of accelerated computing and generative AI, it's essentially the world's most powerful GPU paired with the most versatile CPU.
With its scalable design, the NVIDIA GH200 can handle the most complex generative AI workloads, from large language models (LLMs) and recommender systems to vector databases, graph neural networks (GNNs), and beyond.
"To meet surging demand for generative AI, data centers require accelerated computing platforms with specialized needs," said NVIDIA founder and CEO Jensen Huang. This is precisely the gap that the GH200 aims to fill.
Huang added, "[It] delivers this with exceptional memory technology and bandwidth to improve throughput, the ability to connect GPUs to aggregate performance without compromise, and a server design that can be easily deployed across the entire data center."
Groundbreaking Memory and Bandwidth
The GH200's architecture redefines high-performance computing (HPC). It integrates the cutting-edge Hopper GPU and the versatile Grace CPU into a single superchip – bridged by the lightning-fast, memory-coherent NVIDIA NVLink Chip-2-Chip (C2C) interconnect.
The NVLink-C2C interconnect is the heart of the GH200 Grace Hopper Superchip. The power of its coherent memory is pretty incredible; the interconnect delivers 900GB/s of bidirectional CPU-GPU bandwidth. That's seven times the performance compared to the PCIe Gen5 connections found in conventional accelerated systems! Plus, interconnect power consumption is slashed by more than 5X.
With NVLink-C2C, applications can oversubscribe the GPU's memory, harnessing the high-bandwidth memory of the Grace CPU directly. The GH200 offers up to 480GB of LPDDR5X CPU memory, meaning that – combined with 96GB HBM3 or 144GB HBM3e – the Hopper GPU can directly access up to 624GB of fast memory.
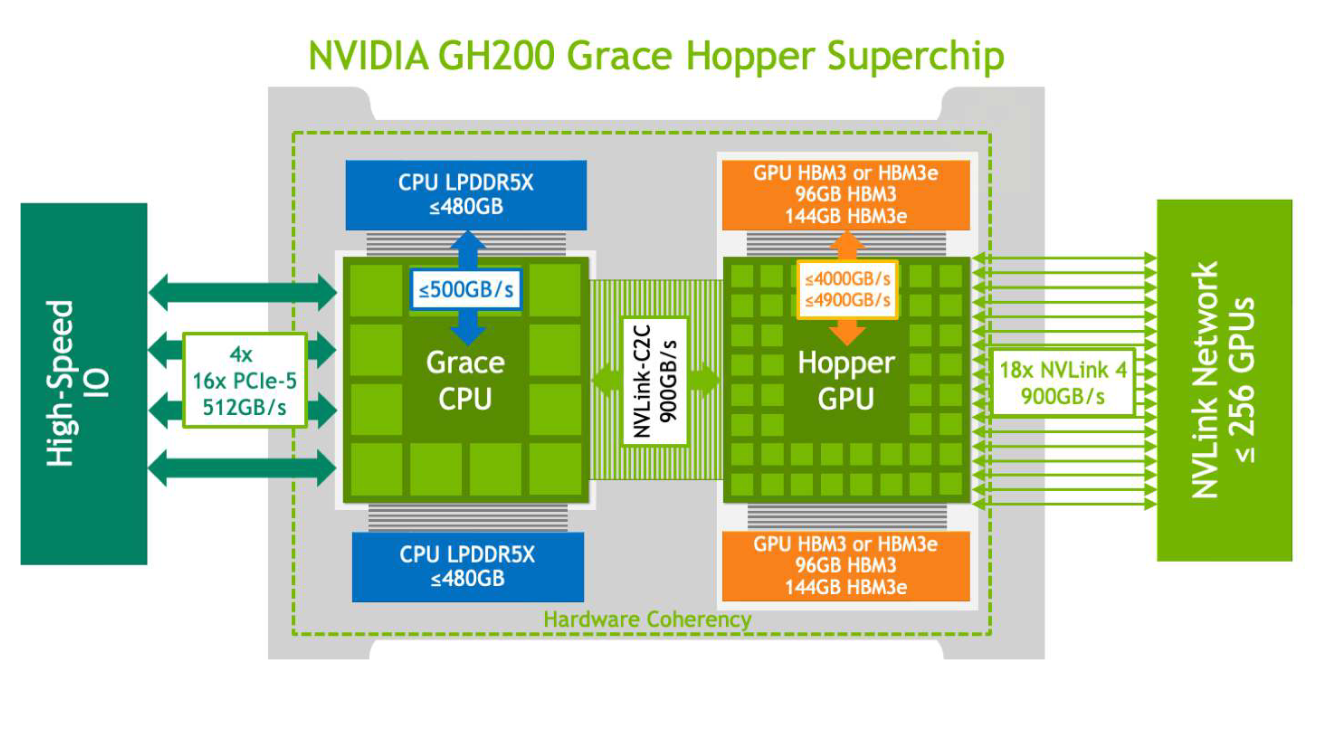
(Image credit: NVIDIA)
Key features of the NVIDIA Grace CPU include:
-
2X the performance per watt of conventional x86-64 platforms
-
72 Neoverse V2 Armv9 cores with up to 480GB of server-class LPDDR5X memory with error-correction code (ECC)
-
Up to 53% more bandwidth at one-eighth the power per GB per second, compared to an eight-channel DDR5 design
Then there's the H100 Tensor Core GPU, based on the new Hopper GPU architecture, which showcases several innovative highlights:
-
Unprecedentedly fast matrix computations by the new fourth-generation Tensor Cores, enabling a wider range of AI and HPC tasks
-
Up to 9X faster AI training and up to 30X faster AI inference with its new Transformer Engine compared to the prior-generation NVIDIA A100
-
Maximized quality of service for smaller workloads thanks to secure Multi-Instance GPU (MIG) partitioning the GPU into isolated, right-size instances
In a nutshell, if you need raw power, you've got it with the GH200. Unfortunately, it's so new that there hasn't really been much comprehensive benchmarking. But let's take a look anyway.
Benchmarks: Pitting the GH200 Against its Main Rivals
On the Linux benchmark site Phoronix, author Michael Larabel published some initial HPC benchmarks run on a GH200 workstation sourced from GPTshop.ai. Testing was done on the Grace CPU performance only.
The GH200 system in question was tested with 72 cores, a Quanta S74G motherboard, 480GB of RAM, and 960GB + 1920GB SAMSUNG SSD drives. (A complete description of specs and environment can be found on the Phoronix site at the above link.) Again, this benchmarking was merely preliminary, as it focused on CPU performance, and no power consumption numbers are available – but there were some interesting results nonetheless.
According to the standard HPCG memory bandwidth benchmark, the GH200 Grace CPU came in at a solid 41.7 GFLOPS.
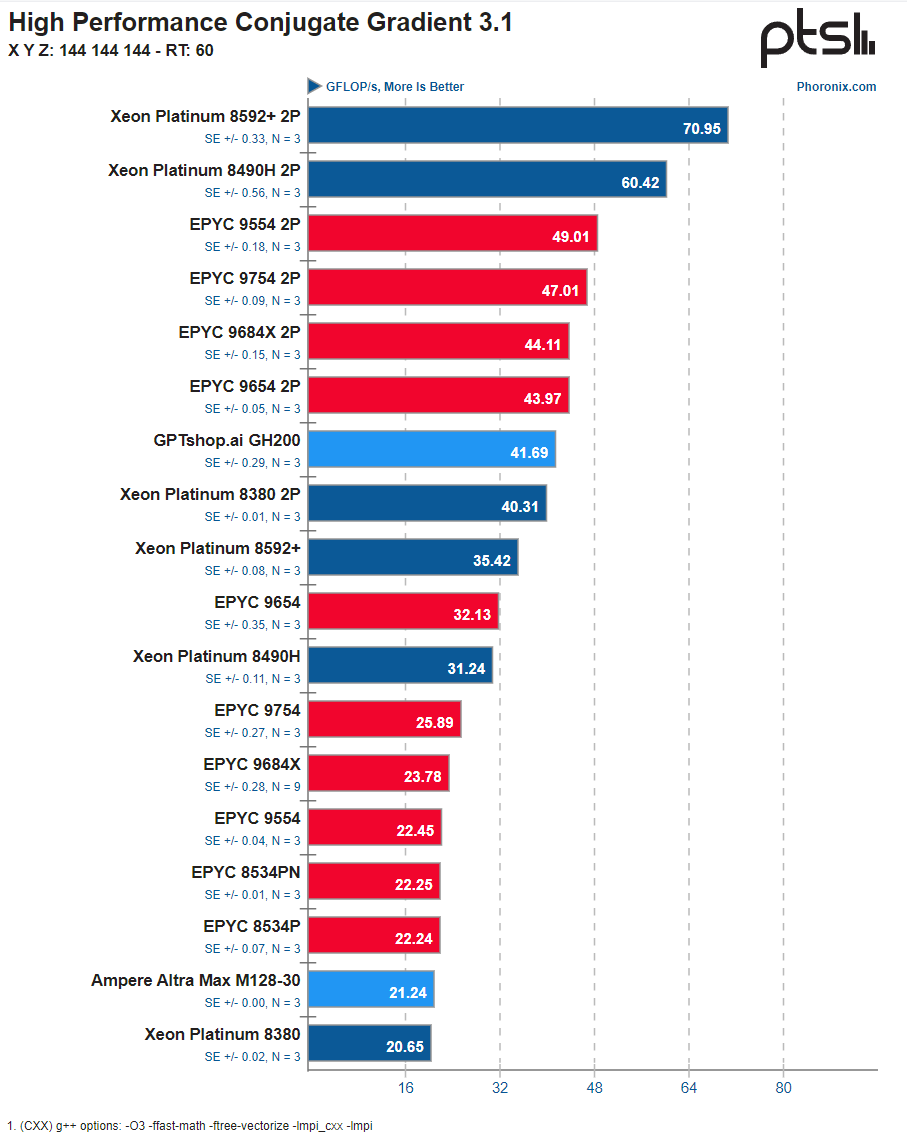
Results for NVIDIA GH200 running HPCG benchmark. (Image credit: Phoronix)
5vFBmCRUcbfgb9PR7NpFoXpSeRSFqr47lr9V1YtOG-k2Aus1jPY1T217XD_EnBKKZKnn8MTFUs-Jx2lMYVR_8Ek4Q9eQcM-kml5l0C2B4wfzwdytunAxtEcGZNfi_pp-GQKy8jTPCrEpqRUtlrk8OXw
Another notable result came from the NWChem benchmark, with the GH200 coming in second place at 1403.5 seconds.
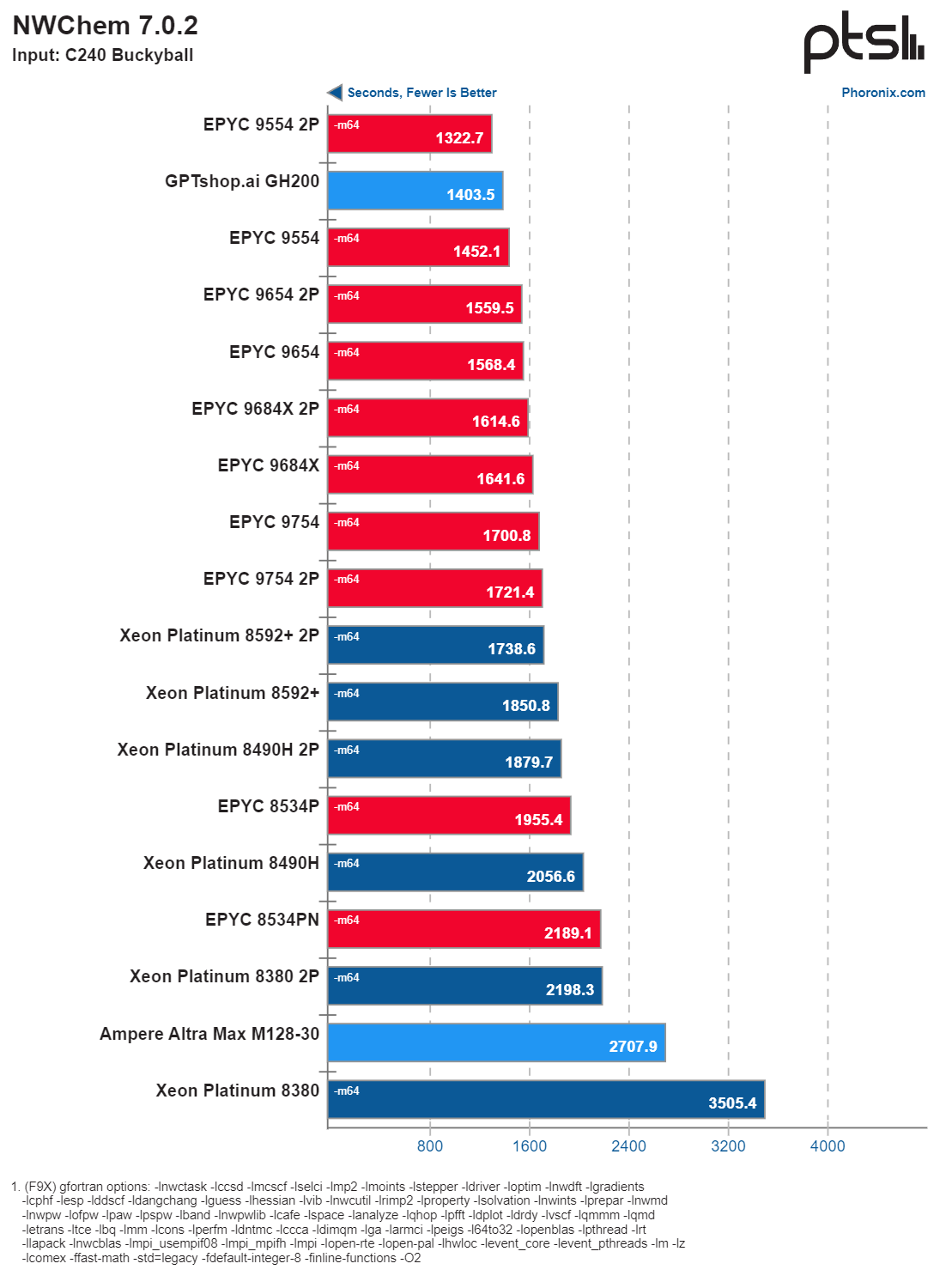
Results for NVIDIA GH200 running NWChem benchmark. (Image credit: Phoronix)
On a geometric mean basis across all the benchmarks, the GH200 Grace CPU performance was perfectly respectable overall.
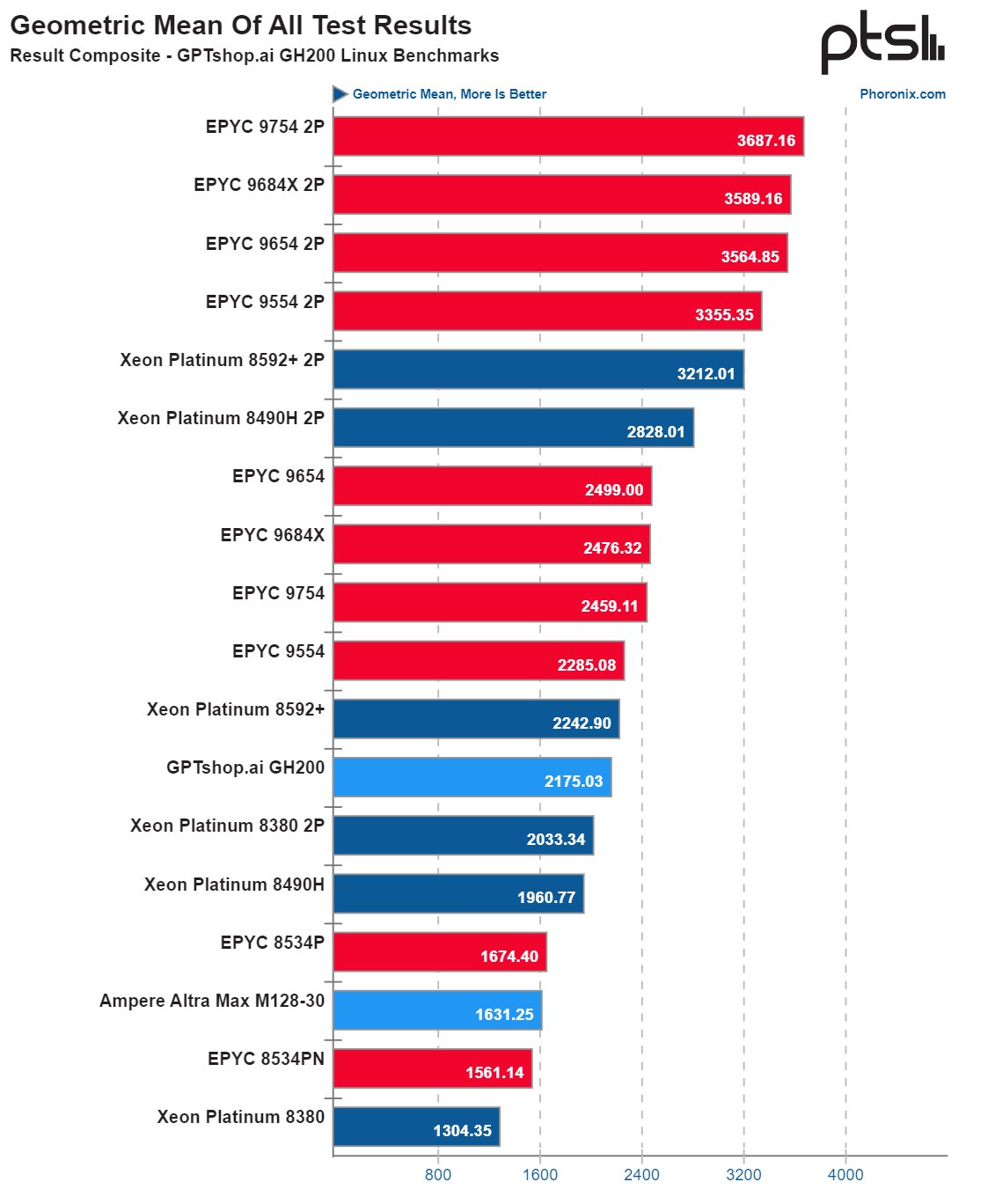
(Image credit: Phoronix)
A set of GPU benchmarks run by researcher Simon Butcher compared performance of the PyTorch ResNet50 training recipes published by NVIDIA. The ImageNet 2012 dataset (150GB) was used, and training was run for 90 epochs, or about an hour. The GH200 showed excellent performance here.
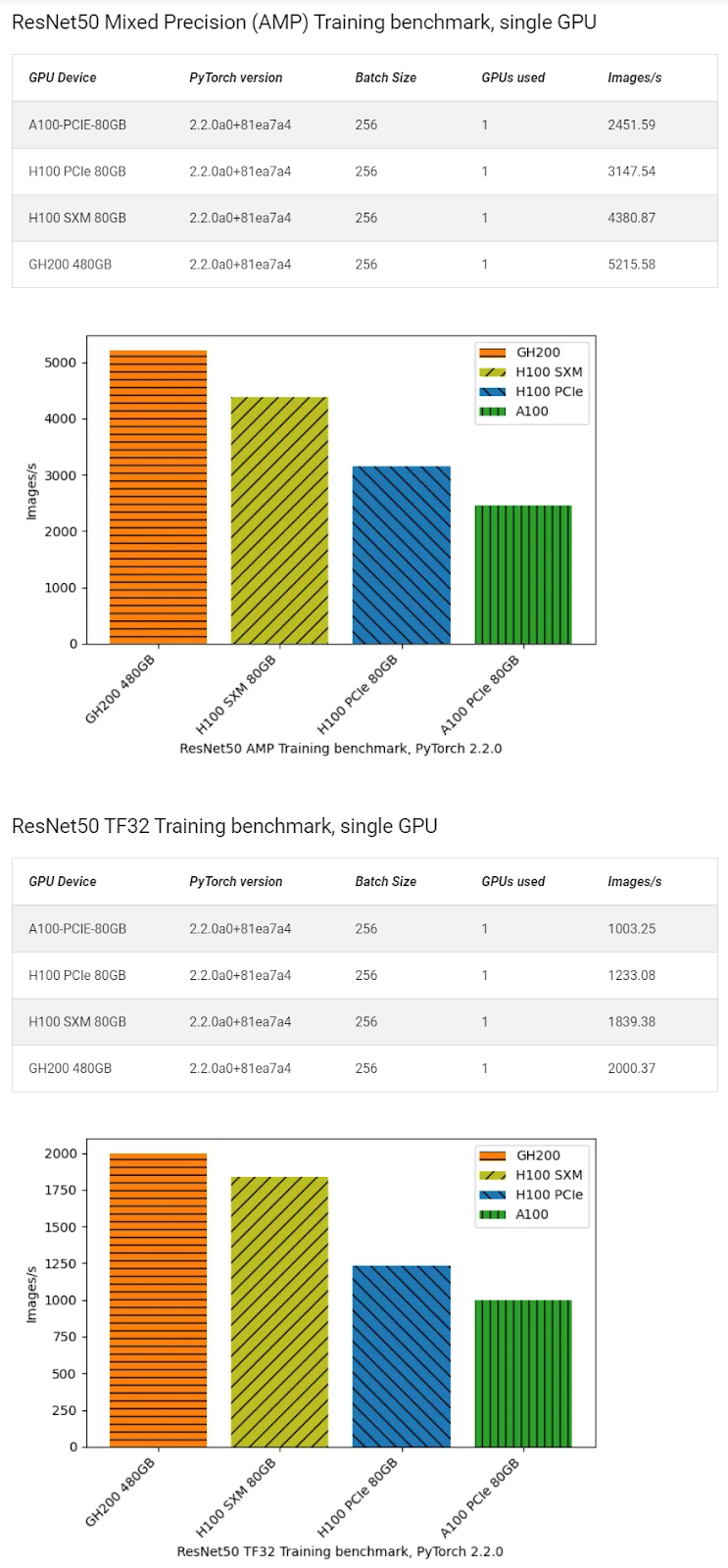
(Image credit: Simon Butcher, Queen Mary University of London)
NVIDIA also published some performance comparisons that may be of interest.
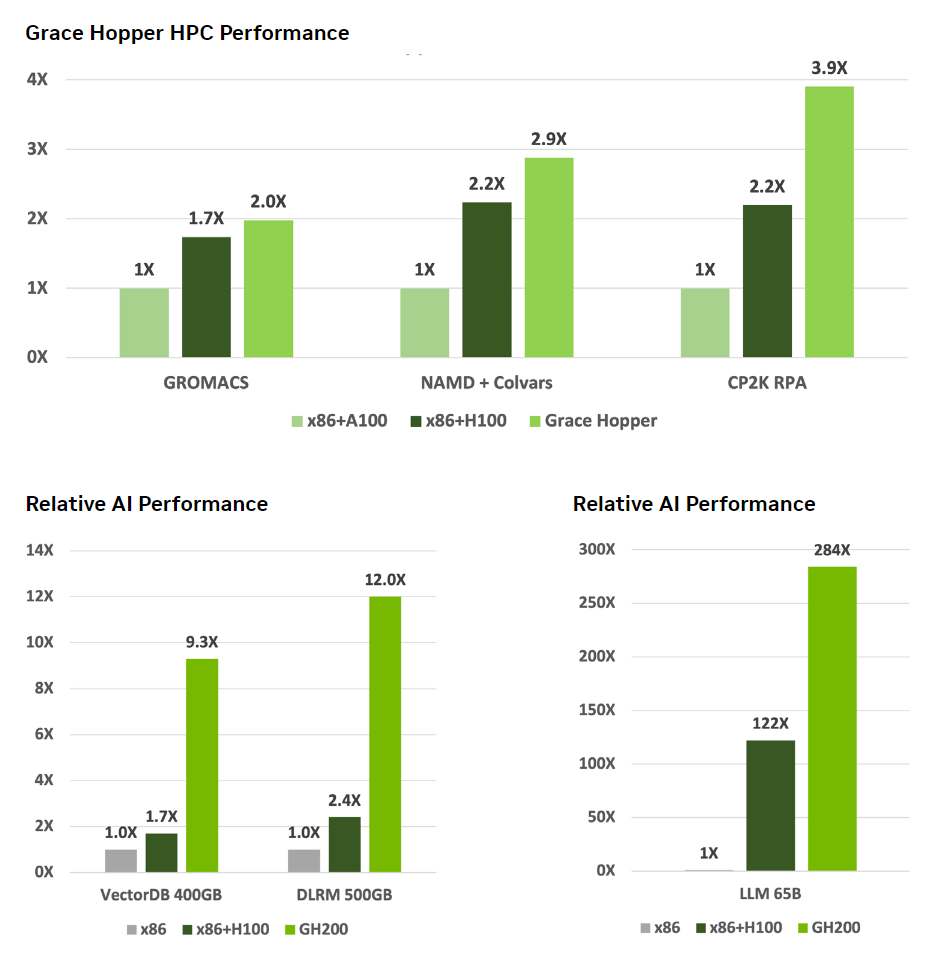
(Image credit: NVIDIA)
Final Thoughts
The NVIDIA GH200 Grace Hopper Superchip delivers the performance required for truly giant-scale AI and HPC applications running terabytes of data. Whether you're a scientist, an engineer, or a massive data center, you'll find it up to the task.
As for what the future holds? Nvidia recently announced the GH200's successor: Grace Blackwell B200, the next-generation data center and AI GPU.
Here at Vast.ai, we're proud to say that we recently added ARM64 and GH200 support to our lineup. On our GPU rental platform, just about anyone can get access to top-tier GPUs at affordable rates for a variety of computational needs. You can skip the cost-prohibitive investment in hardware and get right to work today – we'd love to help you discover the possibilities!


