Serving Online Inference with TGI and Medusa on Vast.ai

Serving Online Inference with TGI and Medusa on Vast.ai
Background
Medusa is a method of specular decoding. Speculative decoding speeds up inference of large language models by having a smaller model multiple tokens and lets the larger model just verify. If the Verification for the large model is cheaper than generating the tokens themselves. If the smaller model is accurate enough, then the cost to generate tokens goes down overall.
Medusa is slightly different than other types of speculative decoding in that it adds a piece of the original model to do the speculation.
TGI is the first major serving framework for large language models that enables Medusa-style speculative decoding.
Speculative decoding comes with a trade-off between adding extra memory used and generation speed. Speculative decoding, including Medusa, requires more overall memory. But if your "draft" model is good enough, then it can provide an excellent speed up opportunity.
Compared to other forms of speculative decoding, Medusa requires a fine-tuned adapter on top of the original model. There exist some of these already that we can use. Be on the lookout for more posts on how to create these adapters from us.
To set up TGI with Medusa on Vast, you can follow the steps outlined in the provided notebook. The notebook will guide you through the process of configuring TGI to serve Medusa and optimizing the setup for your specific use case.
Setup and Querying
First, set up your environment and Vast API key:
pip install --upgrade vastai
Once you create your account, go here to find your API key.
vastai set api-key <Your-API-Key-Here>
For serving a language model, we're looking for a machine with a static IP address, available ports to host on, and a single modern GPU with decent RAM, as we'll serve a single small model. TGI also requires CUDA version 12.1.1 or higher, so we'll filter for that as well. We will query the Vast API to get a list of these types of machines.
vastai search offers 'compute_cap > 800 gpu_ram > 20 num_gpus = 1 static_ip=true direct_port_count > 1 cuda_vers >= 12.1.1'
Deploying the Image
The easiest way to deploy this instance is to use the command line. Copy and paste a specific instance ID you choose from the list above into instance-id below. This medusa model also needs to download gemma-7b-it, which is a gated model. You'll need to accept the terms on gemma-7b-it and pass in your Huggingface API Token into HF_TOKEN=<Your_Huggingface_Token>
.
vastai create instance <instance-id> --image ghcr.io/huggingface/text-generation-inference:latest --env '-p 8000:8000 -e HF_TOKEN={"<Huggingface-Token>"}' --disk 40 --args --port 8000 --model-id text-generation-inference/gemma-7b-it-medusa --speculate 2
Connecting and Testing
To connect to your instance, we'll first need to get the IP address and port number. Once your instance is done setting up, you should see something like this:
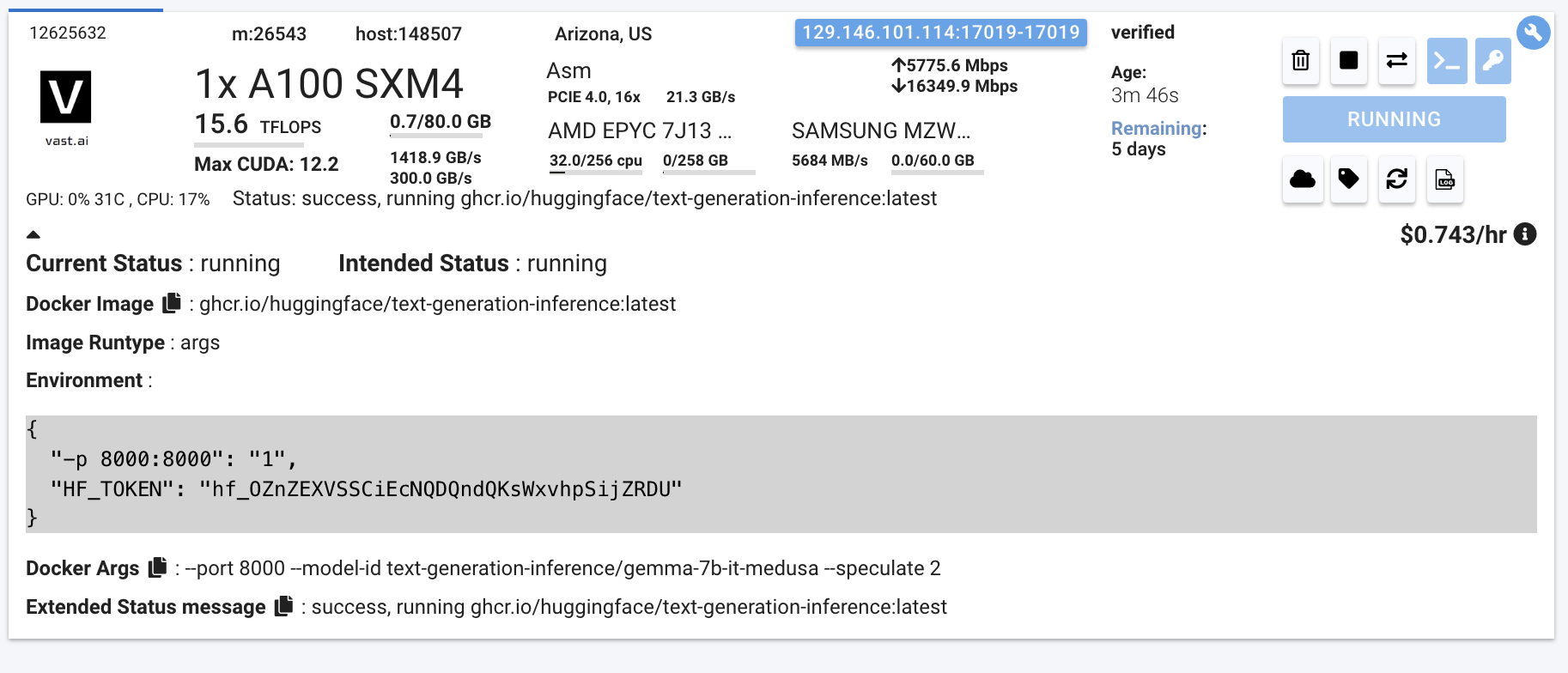
Click on the highlighted button to see the IP address and correct port for our requests.
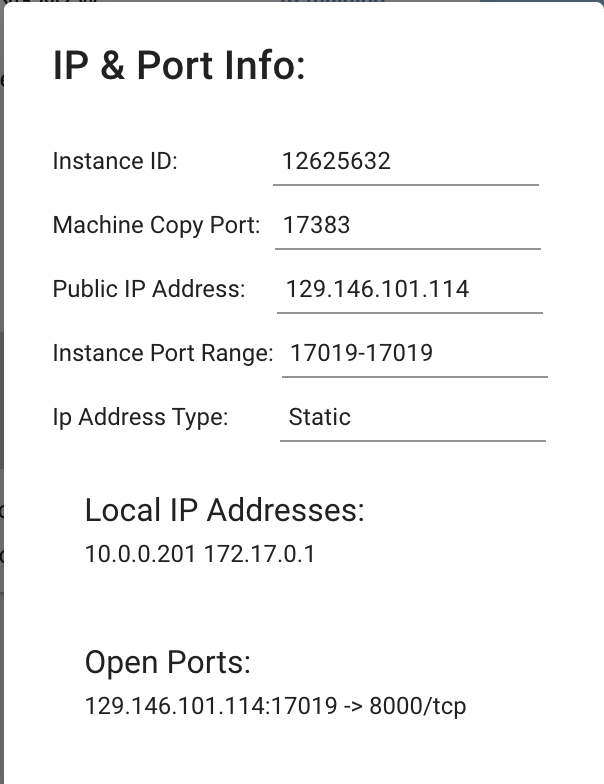
We will copy over the IP address and the port into the cell below.
# This request assumes you haven't changed the model. If you did, fill it in the "model" value in the payload json below
curl -X POST http://<IP-Address>:<Port>/v1/completions -H "Content-Type: application/json" -d '{"model" : "text-generation-inference/gemma-7b-it-medusa", "prompt": "Hello, how are you?", "max_tokens": 50}'
You will see a response from your model in the output. Your model is up and running on Vast!
In the notebook, we include ways to call this model with requests or OpenAI
Other things to look out for with other configurations
If you are downloading a model that needs authentication from the Hugging Face Hub, passing -e HF_token=<Your-Read-Only-Token> within Vast's --env variable string should help.
Sometimes the full context of a model can't be used given the space allocated for TGI on the GPU + the model's size. In those cases, you might want to increase --gpu-memory-utilization, or decrease the max-model-len. Increasing --gpu-memory-utilization does come with CUDA OutOfMemory issues that can be hard to predict ahead of time.
We won't need either of these for this specific model and GPU configuration.
Testing
Copy the IP address from your instance once it is ready, and then we can use the following code to call it. Note that while your server might have ports ready, the model might not have downloaded yet as it is much larger this time. You can check the status of this via the logs to see when it has started serving.
import requests
headers = {
'Content-Type': 'application/json',
}
json_data = {
'model': 'text-generation-inference/gemma-7b-it-medusa',
'prompt': 'Hello, how are you?',
'max_tokens': 50,
}
response = requests.post('http://<Instance-IP-Address>:<Port>/v1/completions', headers=headers, json=json_data)
print(response.content)
Or use OpenAI:
pip install openai
from openai import OpenAIH
# Modify OpenAI's API key and API base to use TGI's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://<Instance-IP-Address>:<Port>/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
completion = client.completions.create(model="text-generation-inference/gemma-7b-it-medusa",
prompt="Hello, how are you?",
max_tokens=50)
print("Completion result:", completion)
Conclusions
Medusa, when paired with TGI on Vast, offers a compelling solution for engineering teams looking to optimize their AI inference costs and improve shipping velocity. The combination of Medusa's faster inference capabilities and TGI's state-of-the-art throughput enables better user experiences and reduced GPU time for serving users and processing data.
By leveraging Medusa's speed advantages, you can achieve higher throughput on GPUs, allowing you to handle more requests simultaneously and deliver faster responses to users. This is particularly valuable in scenarios where low latency and real-time interactions are crucial, such as in chatbots or virtual assistants.
Moreover, the increased throughput provided by Medusa and TGI translates to more efficient utilization of GPU resources. With faster inference times You spend less money for batch workloads and need less GPUs to handle traffic surges. Overall, you can scale your AI applications more effectively.
Vast's affordable compute options further enhance the benefits of using Medusa with TGI. By running Medusa on Vast's infrastructure, you can access cost-effective GPU resources that align with your budget and performance requirements. This allows you to maximize your margins while still delivering high-quality AI experiences to your users.
By leveraging the strengths of Medusa Decoding and the affordability of Vast, you can build cutting-edge AI applications that scale seamlessly and deliver exceptional results.


