Serving Online Inference with Text-Embeddings-Inference on Vast.ai | June 2024

Serving Online Inference with Text-Embeddings-Inference on Vast.ai
Background
Text-Embeddings-Inference is an open source framework for embedding and reranker inference. It is made by Hugging Face and is focused on low latency, high throughput serving with short boot times due to a small docker image.
Embeddings and Re-rankers are often very important for many use cases like RAG, Information Retrieval, Search, and dataset cleaning + exploration.
This guide will show you how to setup Text-Embeddings-Inference to serve an embedding model for online inference on Vast. We reference a notebook that you can use here.
Setup and Querying
First, we setup our environment and vast api key
pip install --upgrade vastai
Once you create your account, you can go here to find your API Key.
vastai set api-key <Your-API-Key-Here>
For serving, we're looking for a machine that has a static IP address, ports available to host on, plus a single modern GPU since we're going to serve a single small model. Text-Embeddings-Inference also requires Cuda version 12.2 or higher, so we will filter for that as well. We'll query the Vast API to get a list of these types of machines.
vastai search offers 'compute_cap >= 800 num_gpus = 1 static_ip=true direct_port_count > 1 cuda_vers >= 12.2'
Deploying the Image:
The easiest way to deploy this instance is to use the command line. Copy and Paste a specific instance id you choose from the list above into instance-id below.
We also told Text-Embeddings-Inference to serve on port 8000 as that is the default port for the OpenAI SDK, but it would normally serve on port 80 instead. Feel free to change this as you like
vastai create instance <instance-id> --image ghcr.io/huggingface/text-embeddings-inference --env '-p 8000:80' --disk 16 --args --model-id jinaai/jina-embeddings-v2-base-en
Compute Architecture and Server Image Selection:
Text-Embeddings-Inference does offer support for multiple different GPU Types from Nvidia. However it is often best to match up the hardware you're using with the specific image to increase performance and reliability. They give you the recommended image for each GPU here
Connecting and Testing:
To connect to your instance, we'll first need to get the IP address and port number. Once your instance is done setting up, you should see something like this:

Click on the highlighted button to see the IP address and correct port for our requests.
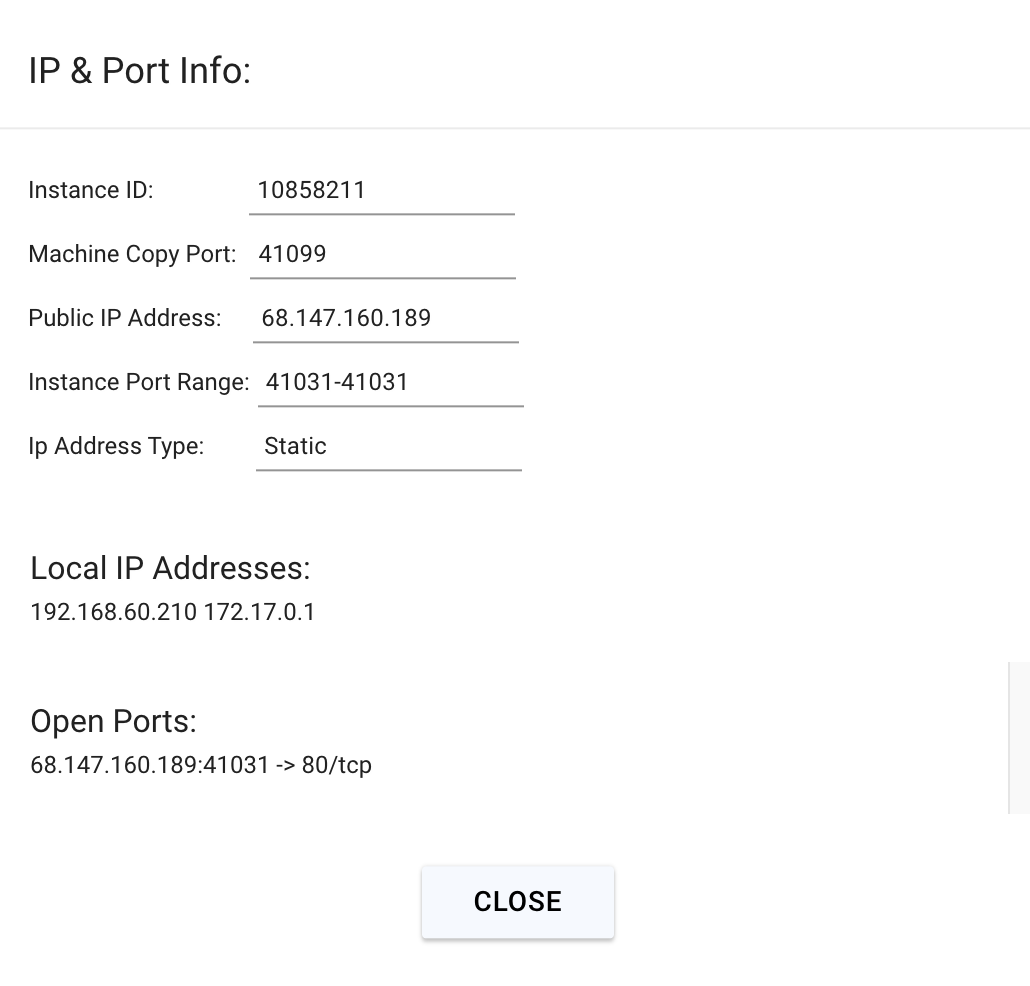
We will copy over the IP address and the port into the cell below.
curl <Instance-IP-Address>:<Port>/embed -X POST -d '{"inputs":"What is Deep Learning?"}' -H 'Content-Type: application/json'
You will see a response from your model in the output, which will be the embedding of your query. Your model is up and running on Vast!
Connecting with the OpenAI SDK
The OpenAI SDK also allows for generating embeddings. We can use it as well with the following code.
pip install openai
from openai import OpenAI
# Modify OpenAI's API key and API base to use vLLM's's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://<Instance-IP-Address>:<Port>/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
model = "jinaai/jina-embeddings-v2-base-en"
embeddings = client.embeddings.create(model=model, input="What is Deep Learning?")
print(embeddings)
This is great, as it helps us integrate our embeddings into applications that use the OpenAI SDK.
Next Steps:
Embeddings and Re-Ranking are fundamental building blocks to many different ways of building AI applications. Stay Tuned as we cover these topics more in depth!


