Everything You Need to Know About the NVIDIA Blackwell Ultra B300

What makes a powerful GPU? For years, GPU generations were often judged by how much faster they could train AI models. But today's AI workloads are increasingly dominated by inference, where memory capacity, latency, and efficiency matter as much as raw compute.
The NVIDIA Blackwell Ultra B300 reflects that reality. Designed to tackle the explosive growth of agentic AI and the most complex reasoning workloads, it enables larger models, longer context windows, and higher throughput than any single GPU before it.
Here's everything you need to know about the B300.
What Is the NVIDIA Blackwell Ultra B300?
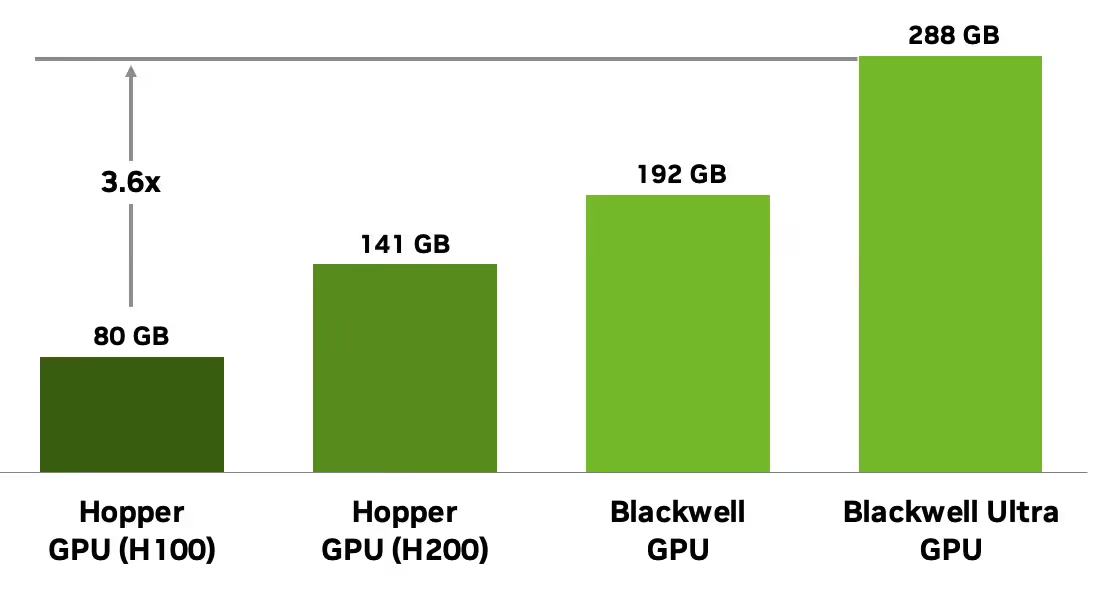
Available through partner systems beginning in the second half of 2025, the Blackwell Ultra B300 is one of the most powerful GPUs in NVIDIA's lineup. It features an enormous 288 GB of HBM3e memory. That's 50% more than the B200, about twice the capacity of the H200, and 3.6x that of the H100.
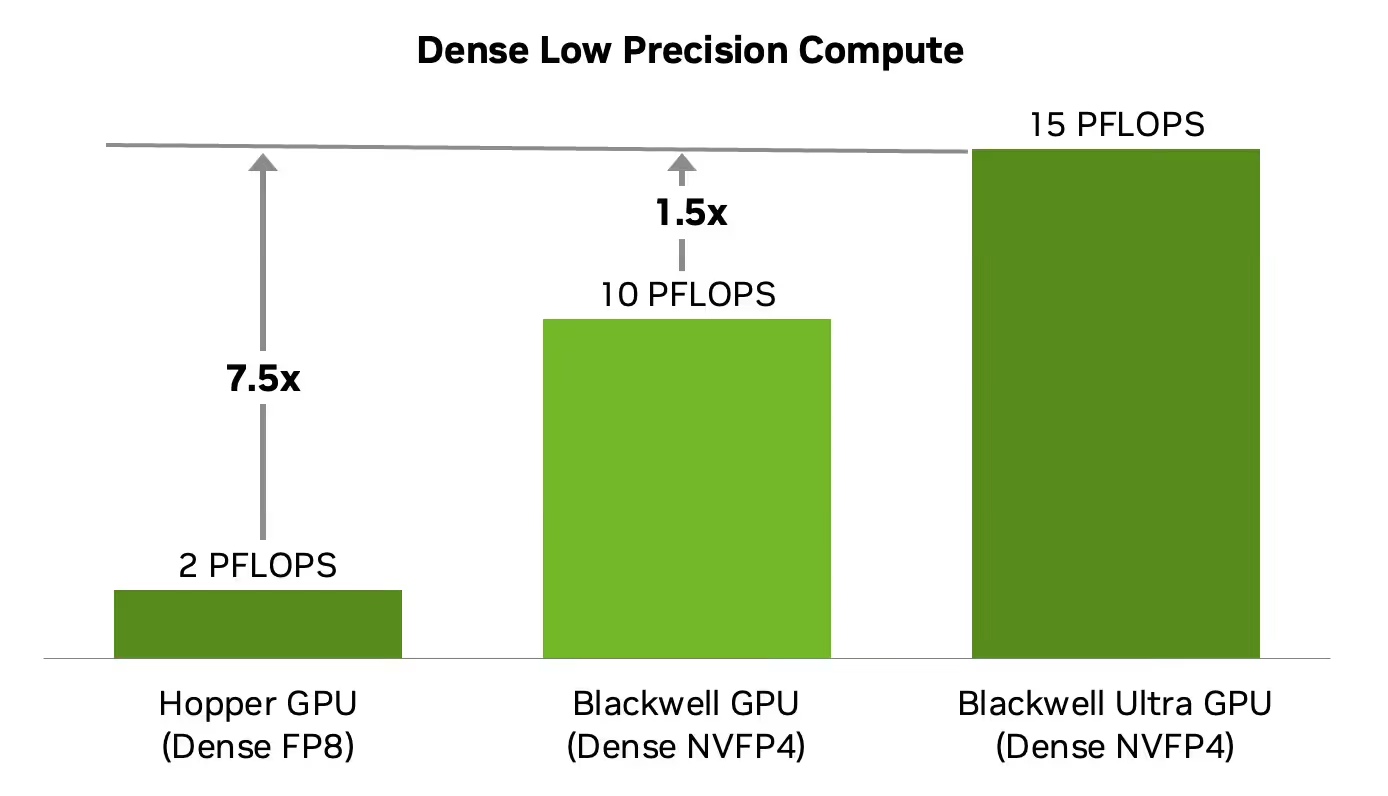
Compared to Hopper and standard Blackwell, the Blackwell Ultra also delivers substantial gains in dense low-precision compute performance.
For reference, each B300 GPU features:
- 288 GB of HBM3e memory
- 160 streaming multiprocessors
- 8 TB/s memory bandwidth
- 15 PFLOPS dense FP4 performance
- 7 PFLOPS dense FP8 performance
- 3.5 PFLOPS dense FP16 performance
- 5th-generation Ultra Tensor Cores
- 20,480+ CUDA cores
- 1.8 TB/s 5th-gen NVLink bandwidth
- NVIDIA ConnectX-8 networking
- 1,400W TDP
In addition, the B300's Blackwell Ultra architecture incorporates several features designed for modern AI inference. These include fifth-generation Tensor Cores with native NVFP4 support, a second-gen Transformer engine, a dual-die design linked by a 10 TB/s on-package interface, and faster PCIe Gen 6 and NVLink interconnects for scaling across GPUs.
But the memory capacity is the big news when it comes to the NVIDIA B300.
Why the B300's Memory Matters
Memory capacity increasingly determines what AI workloads can run efficiently. The massive 288 GB of memory attached to each B300 GPU is particularly valuable for frontier models, retrieval-augmented generation (RAG) systems, and trillion-parameter mixture-of-experts (MoE) models that require substantial memory for weights, activations, and key-value (KV) caches.
As context windows grow longer and reasoning models become more sophisticated, memory often becomes the limiting factor before compute does. When KV caches can't fit on-device, they spill onto external memory tiers like system RAM or NVMe storage, increasing latency and degrading throughput.
However, a single B300 can fit a full 70B-parameter model in FP16 with plenty of room remaining for KV cache storage and batching - something that previous-generation GPUs could typically only achieve through quantization and model sharding. The result is lower latency variability and higher sustained throughput as workload complexity increases.
This advantage compounds in multi-GPU systems. The B300 is the module that powers the NVIDIA DGX B300, a server combining eight B300 GPUs into a single system with over 2 TB of total GPU memory. More on-device memory per GPU means there's less need for complex model parallelism, which reduces the cross-GPU communication overhead that can constrain performance at scale.
With the DGX B300, organizations can run 400B+ parameter frontier models entirely within GPU memory. But as impressive as it is, the B300 does have some drawbacks.
The Hidden Cost of B300 Performance
The NVIDIA Blackwell Ultra B300 represents a generational leap in memory and compute, but it's also a generational leap in infrastructure demand.
Each B300 GPU can draw between 1,100W and 1,400W of power depending on the chassis form factor, with a TDP of 1,400W. That's 40% higher than the B200's 1,000W. Not to mention, the eight-GPU DGX B300 draws about 14 kW under peak load.
At this level, liquid cooling is mandatory and has real implications for total cost of ownership.
Consider that a single B300 GPU costs around $50,000, and a fully configured DGX B300 costs in the range of $300,000 to $500,000 - before even factoring in the hidden cost of liquid cooling infrastructure, power delivery, and/or facility upgrades.
Granted, the B300 is energy-efficient per FLOP: according to NVIDIA, the rack-scale GB300 NVL72 boasts 5x throughput per megawatt versus Hopper-generation systems. But efficiency gains don't necessarily make up for the 2x higher power draw and greater rack-level density as deployment scale increases.
The bottom line is that cooling and power delivery must be addressed before you can even think about taking advantage of the B300's performance. Another consideration: when does it make sense to use the B300?
What Workloads the B300 Is Built For
The B300 is particularly well suited for use cases such as:
- Large model inference with 70B+ parameters, with reduced reliance on quantization or sharding across multiple GPUs.
- Reasoning models with large KV cache requirements, allowing for higher output quality and lower latency while maintaining longer context windows.
- High-throughput inference APIs where the FP4 compute advantage means using fewer GPUs at a given request volume.
- Multi-node training environments where the high inter-node bandwidth eases communication bottlenecks.
These workloads are where the B300's performance can actually justify the infrastructure investment. But on-prem deployment isn't for everyone.
Accessing the B300 Without the Infrastructure Burden
For many teams, the NVIDIA Blackwell Ultra B300 is the right hardware at the wrong price. The operational overhead of running these flagship datacenter-grade GPUs can be prohibitive for all but the largest organizations with the deepest pockets.
That's where Vast.ai comes in. Rather than owning and operating the hardware yourself, you get on-demand access to B300 GPUs from a globally distributed fleet at a fraction of the cost, with flexible configurations ranging from one to eight B300s. And if you prefer not to manage GPU instances at all, Vast.ai Serverless can automatically orchestrate the provisioning of GPU workers to match your dynamic workloads in real time.
Leverage Blackwell Ultra's massive memory capacity and impressive FP4 inference performance without the upfront capital expense - and experiment and scale faster while paying only for the compute you actually use.
Ready to get started? Explore available B300 instances on Vast.ai today.


