Meta Launches Llama 3.1: A New Era in Open-Source AI

Breaking New Ground with Llama 3.1
This week, Meta launched the Llama 3.1 collection of large language models (LLMs). It consists of three new models – pre-trained and instruction-tuned text in/text out open-source generative AI models – with parameter counts of 8B, 70B, and 405B.
According to Meta, the flagship 405B version is "the world's largest and most capable openly available foundation model."
Open-Source Approach and Innovation
CEO Mark Zuckerberg champions the open-source approach, predicting that it will eventually become the industry standard, much like Linux did for operating systems. He asserts that open-source AI models not only develop more rapidly but also offer greater innovation potential compared to their proprietary, closed-source counterparts.
The global AI community has indeed been energized by the release of Llama 3.1, with plenty of discussions and exploration around its potential. Here's what you need to know!
Earlier Goals and Recent Achievements
Earlier this year, when the first, smaller, Llama 3 models were released (Llama 2), Meta stated that its goal in the near future is "to make Llama 3 multilingual and multimodal, have longer context, and continue to improve overall performance across LLM capabilities such as reasoning and coding."
With Llama 3.1, it's made great strides toward achieving that goal. The LLM isn't multimodal yet, but it does boast new multilingual capabilities (in Spanish, Portuguese, Italian, German, and Thai), as well as expanded tool use and drastically increased context length. Trained using over 16,000 of NVIDIA's H100 GPUs on a massive dataset of 15 trillion tokens, the 405B model is significantly more complex and powerful than its predecessors.
Performance Benchmarks
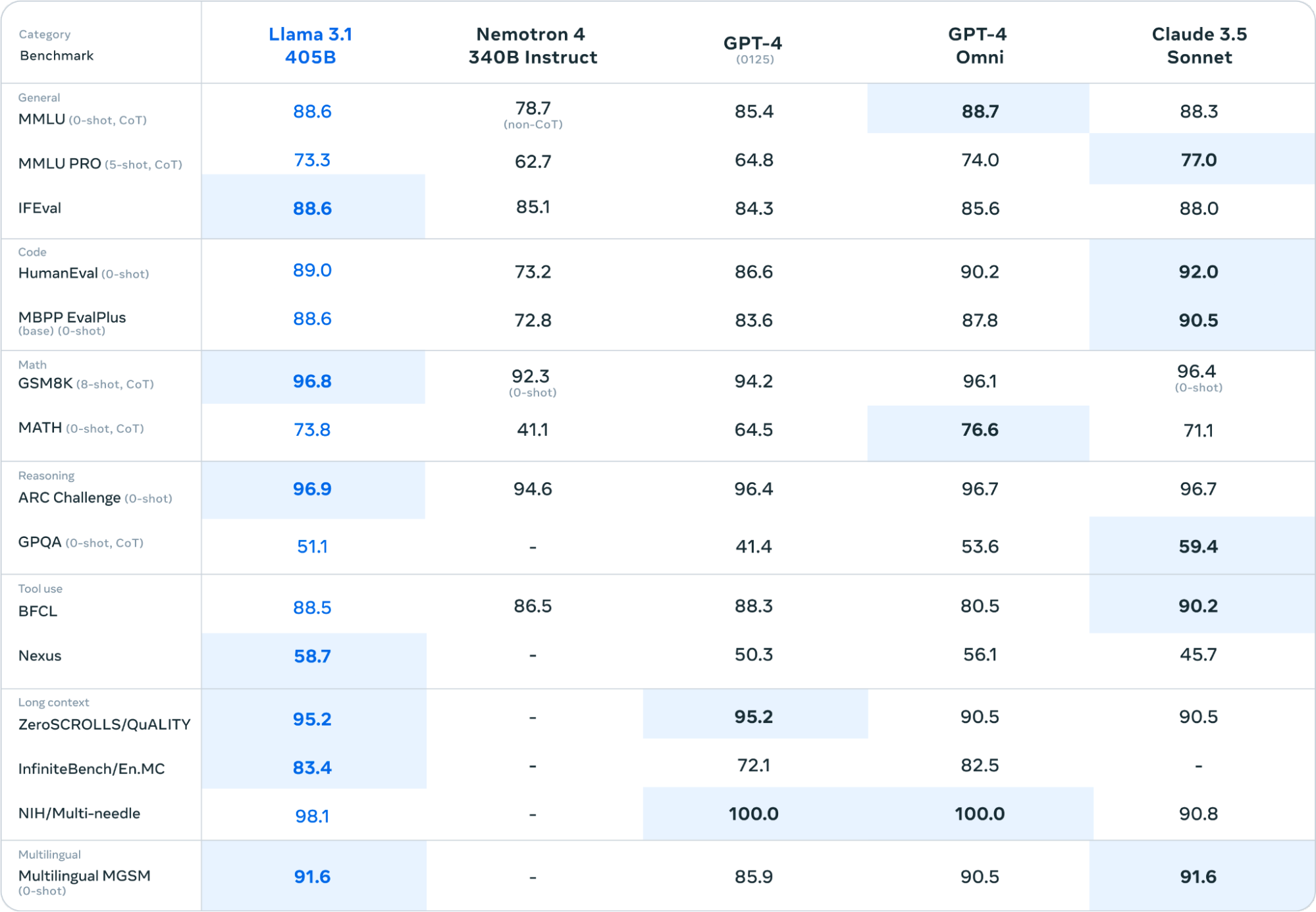
Meta says that Llama 3.1 405B outperforms OpenAI's GPT-4 and GPT-4o as well as Anthropic's Claude 3.5 Sonnet on a number of benchmark tests. And across a range of different tasks, it's reportedly "competitive with" its closed-source rivals.
Here's how the 405B model compares to other cutting-edge LLMs across commonly used benchmarks (with Gemini not included because Meta had difficulty using Google's APIs to replicate its results):
Model Architecture and Design
In a blog introducing Llama 3.1, Meta specified that the model's full training stack was "significantly optimized." Design choices prioritized scalability and simplicity for the model development process.
For instance, to maximize training stability, Llama 3.1 uses a standard decoder-only transformer model architecture with minor adaptations instead of a mixture-of-experts model. Meta also adopted an iterative post-training procedure, using supervised fine-tuning and direct preference optimization for each round. The result was the creation of superior-quality synthetic data with each iteration, enhancing the performance of every capability.
The 405B model itself was even used to improve the post-training quality of the smaller 70B and 8B models.
Notably, in order to facilitate large-scale production inference for a model at the 405B's scale, Meta transitioned from 16-bit (BF16) to 8-bit (FP8) numerics. This effectively reduces the compute requirements and enables the model to run within a single server node.
Users can now enjoy a longer context window, as well. The Llama 3.1 models have a context length that's been expanded from 8,192 tokens in Llama 3 to 128,000 tokens in Llama 3.1. That's about 16 times as much!
In fact, the expanded context length is now much greater than that of GPT-4 and about equal to what enterprise users get with GPT-4o – and pretty comparable to the 200,000 token window of Claude 3.
On top of that, periods of high demand won't affect access because Llama 3.1 can be deployed on your own hardware or chosen cloud provider. Generally, there won't be broad usage limits, either.
Using and Building with Llama 3.1 405B
As such a powerful model, the 405B will require significant compute resources and developer expertise to work with it. Meta explicitly states that it wants users to get the most out of it – to take advantage of its advanced capabilities and start building immediately. The following are some possibilities:
- Real-time and batch inference
- Supervised fine-tuning, including on a specific domain
- LLM-as-a-judge (evaluation of your model for your specific application)
- Continual pre-training
- Retrieval-Augmented Generation (RAG)
- Function calling
- Synthetic data generation
Ahmad Al-Dahle, Meta's VP of generative AI, predicts that knowledge distillation will be a popular use of the 405B model for developers. That is, it can be used as a larger "teacher" model that distills its knowledge and emergent abilities into a smaller "student" model with faster and more cost-effective inference.
Another example: Al-Dahle says that Llama 3.1 can integrate with a search engine API to "retrieve information from the Internet based on a complex query and call multiple tools in succession in order to complete your tasks." If you ask the model to plot the number of homes sold in the United States over the last five years, "it can retrieve the [web] search for you and generate the Python code and execute it." Not bad.
The Llama ecosystem also offers turnkey directions for various use cases and advanced workflows for anyone to use. Meta has partnered with projects like vLLM, TensorRT, and PyTorch to build in support right from the start, making it easier for users to get started.
Moving Forward
Ultimately, Llama 3.1 represents an important leap forward in the pursuit of open, accessible, and responsible AI innovation.
There's some debate as to whether open-source models are safer than closed source in the long run. Mark Zuckerberg believes they are. And numerous organizations have signed on to the AI Alliance with Meta and IBM to promote this vision for the future of open AI – including CERN, Hugging Face, Intel, Linux Foundation, NASA, and Oracle.
Here at Vast.ai, we appreciate the accessibility of these open-source LLMs – along with the collaboration of the community around them. Our own mission aligns with this philosophy of democratizing AI for everyone.
To that end, we're pleased to be able to offer the open-source Text Generation Interface (TGI) framework on Vast, so you can serve LLMs like Llama 3.1 and run your own models with much more affordable compute.
Check out our guide on Serving Online Inference with TGI on Vast.ai!


