Serving Online Inference with TGI on Vast.ai | June 2024

Serving Online Inference with TGI on Vast.ai
Background
TGI is an open source framework for Large Language model inference. It specifically focuses on throughput for serving, automatic batching, and ease of use with the Huggingface Ecosystem.
TGI provides an OpenAI compatible server, which means that you can integrate it into chatbots, and other applications
As companies build out their AI products, they often hit roadblocks like rate limits and cost for using these models. With TGI on Vast, you can run your own models in the form factor you need, but with much more affordable compute. As inference grows in demand with agents and complicated workflows, using Vast is great for performance and affordability where you need it the most.
This guide will show you how to setup TGI to serve an LLM on Vast. We reference a notebook that you can use here. It is based upon our guide and notebook for Serving vLLM, so that users can see the small differences they need to handle if they care to switch.
Setup and Querying
First, we setup our environment and vast api key
pip install --upgrade vastai
Once you create your account, you can go here to find your API Key.
vastai set api-key <Your-API-Key-Here>
For serving an LLM, we're looking for a machine that has a static IP address, ports available to host on, plus a single modern GPU with decent RAM since we're going to serve a single small model. TGI also requires Cuda version 12.1 or higher, so we will filter for that as well. We'll query the vast API to get a list of these types of machines.
vastai search offers 'compute_cap > 800 gpu_ram > 20 num_gpus = 1 static_ip=true direct_port_count > 1 cuda_vers >= 12.1'
Deploying the Image:
The easiest way to deploy this instance is to use the command line. Copy and Paste a specific instance id you choose from the list above into instance-id below.
We also told TGI to serve on port 8000 as that is the default port for the OpenAI SDK, but TGI would normally serve on port 8080 instead.
vastai create instance <instance-id> --image ghcr.io/huggingface/text-generation-inference:1.4 --env '-p 8000:8000' --disk 40 --args --port 8000 --model-id stabilityai/stablelm-2-zephyr-1_6b
Connecting and Testing:
To connect to your instance, we'll first need to get the IP address and port number. Once your instance is done setting up, you should see something like this:

Click on the highlighted button to see the IP address and correct port for our requests.
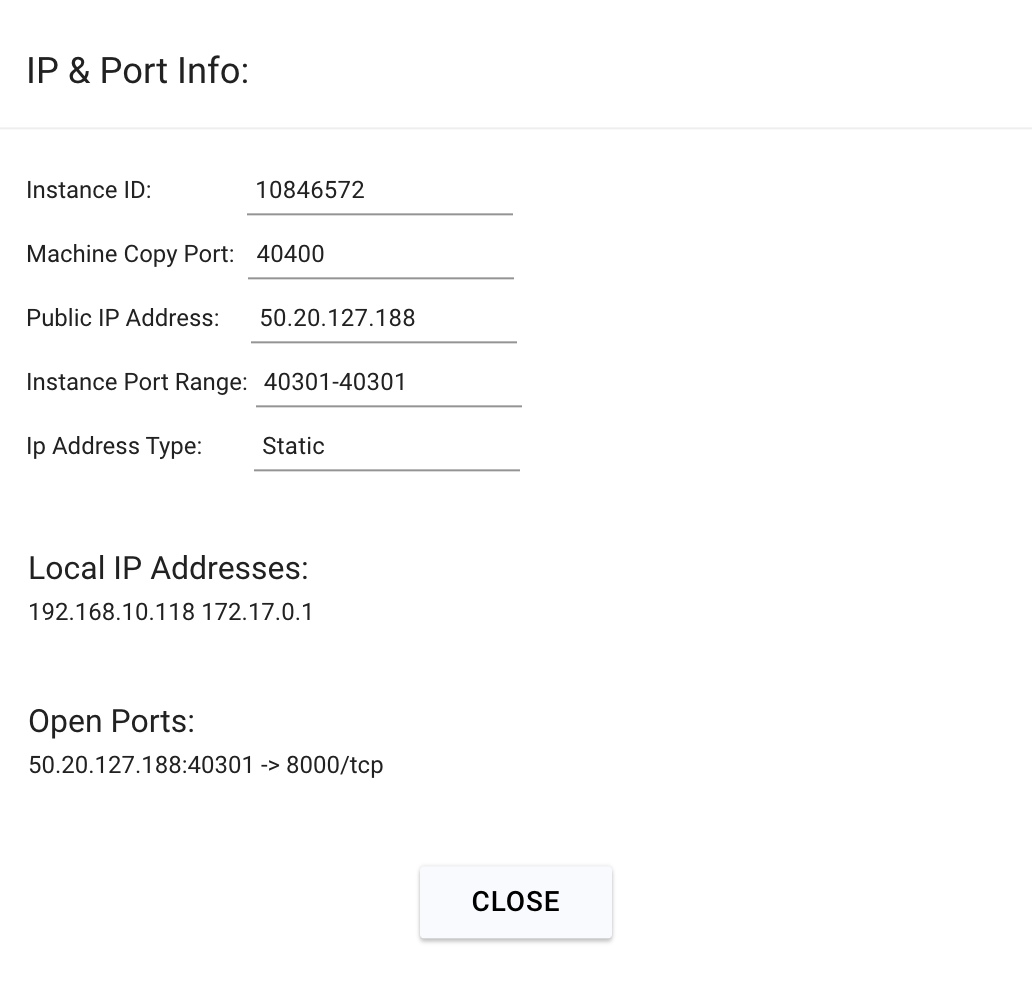
We will copy over the IP address and the port into the cell below.
# This request assumes you haven't changed the model. If you did, fill it in the "model" value in the payload json below
curl -X POST http://<IP-Address>:<Port>/v1/completions -H "Content-Type: application/json" -d '{"model" : "stabilityai/stablelm-2-zephyr-1_6b", "prompt": "Hello, how are you?", "max_tokens": 50}'
You will see a response from your model in the output. Your model is up and running on Vast!


