NVIDIA H100 vs. H200: Two Hopper-based Heavyweights

The H100 and H200 GPUs represent the top end of NVIDIA's current lineup for AI and high-performance computing (HPC). Both are designed for serious, large-scale workloads – from training foundation models to running complex scientific simulations.
At a glance, the two GPUs may appear similar, but for those working across enterprise environments or pushing the boundaries of exascale computing, the differences between them can have a major impact on performance and scalability.
Today, we're taking a look at how the H100 and H200 stack up against each other to help you decide which of these two heavyweights may be the better fit for your needs.
NVIDIA H100: The Proven Performer
The H100 GPU made waves when it launched in March 2023. Quickly adopted by big names like OpenAI, Meta, and Stability AI, it became the engine behind some of the most advanced generative AI systems in production today.
Built on NVIDIA's innovative Hopper architecture, the H100 was engineered for scale, handling everything from trillion-parameter language models to high-throughput inference. It introduced fourth-gen Tensor Cores and a dedicated Transformer Engine, designed to accelerate deep learning workloads with speed and FP8 precision.
The H100 boasts up to a 30X boost in performance for large language models (LLMs) over its predecessor, the A100 GPU, according to NVIDIA. This massive improvement helped cement the H100 as the new standard for foundational model training, and to this day, it's still one of the very best GPUs on the market.
Some of the H100's more notable features include:
-
80 GB of HBM3 memory, with some models offering up to 94 GB.
-
3.35 TB/s of memory bandwidth to handle data-intensive workloads.
-
Fourth-gen Tensor Cores with superior throughput performance, along with an advanced Transformer Engine and FP64 and FP8 capabilities to reduce memory usage.
-
PCIe Gen5 and fourth-gen NVLink (with 900 GB/s of GPU-to-GPU interconnect), as well as NDR Quantum-2 InfiniBand networking for efficient scalability.
-
Multi-Instance GPU (MIG) support for secure partitioning into up to 7 isolated right-size instances that maximize quality of service for multi-tenant environments and parallel workloads.
If your projects involve massive datasets, large-scale simulations, or advanced AI training for foundational models, the H100 has proven itself as a reliable, high-performance solution. But with the arrival of the H200 in late 2024, NVIDIA has taken things a step further, introducing upgrades that push the envelope even more for memory-intensive and high-throughput workloads.
We ran a side-by-side comparison of inference performance on the DeepSeek R1 Distill Llama 8B model using vLLM with both NVIDIA H100 and H200 GPUs on Vast.ai.
Benchmark Configuration
- Model:
deepseek-ai/DeepSeek-R1-Distill-Llama-8B - Requests: 5,000
- Batch: 512
- Input Tokens: 16
- Output Tokens: 128
- Backend:
vLLM
Results
Metric | H100 | H200 |
|---|---|---|
Benchmark Duration | 45.28 s | 40.02 s |
Request Throughput | 110.42 req/s | 124.93 req/s |
Output Throughput | 13,650 tok/s | 15,435 tok/s |
Total Throughput | 15,416 tok/s | 17,434 tok/s |
NVIDIA H200: The Supercharged Successor
The H200 builds directly on the foundation laid by the H100, bringing meaningful improvements that target one of the biggest bottlenecks in AI and HPC workloads: memory.
While it shares the same Hopper architecture as the H100 and has similar core compute specs, the H200 significantly increases both memory capacity and bandwidth, two factors that become critical when operating at enterprise scale or pushing into exascale territory.
Equipped with 141 GB of HBM3e memory and 4.8 TB/s of bandwidth, the H200 nearly doubles the memory of the H100 and delivers about 1.4X faster data access. Early benchmarks reflect that improvement. In MLPerf testing using Llama 2 70B, the H200 achieved over 31,000 tokens per second – about 45% faster than the H100.
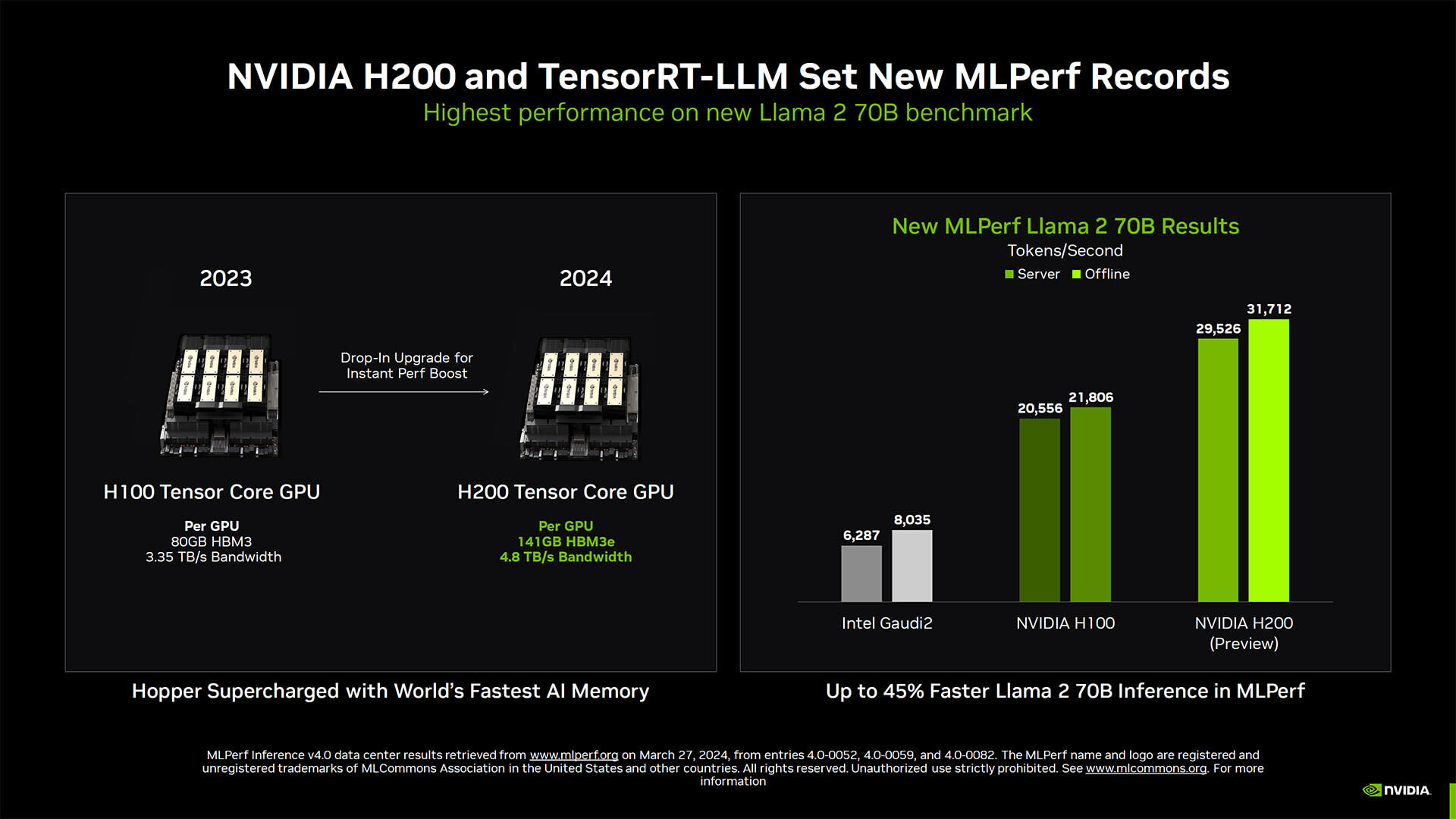
The H200 retains all of the architectural strengths of the H100, including fourth-gen NVLink, PCIe Gen5, MIG support, and full Tensor Core and Transformer Engine capabilities. But for developers and organizations looking to squeeze out more performance without overhauling their infrastructure, the H200 offers a straightforward upgrade path with measurable gains.
To recap, here are a few advantages of the H200:
-
141 GB of HBM3e memory at 4.8 TB/s – nearly double the capacity of the H100, with 1.4X more memory bandwidth.
-
Up to 1.9X the inference performance of the H100 when handling LLMs, with more efficient processing per token and per inference cycle.
-
50% reduced energy use and total cost of ownership (TCO) due to improved thermal management and energy efficiency.
-
Drop-in compatibility with existing Hopper-based systems, enabling accelerated performance gains in H100-optimized infrastructure with minimal or no additional changes.
In short, the H200 represents a meaningful leap beyond the H100 in memory capacity, bandwidth, and throughput, bringing a new level of performance to AI and HPC workloads. That comes at a premium price, of course. But if you're weighing the tradeoffs between the two GPUs in terms of specs alone, let's take a side-by-side look at how they compare.
H100 vs. H200: Key Specs Compared
For reference, here's a quick outline of the various features and specs of the NVIDIA H100 and H200:
Specification | H100 | H200 |
|---|---|---|
GPU Architecture | Hopper | Hopper |
GPU Memory | 80 GB HBM3 | 141 GB HBM3e |
GPU Memory Bandwidth | 3.35 TB/s | 4.8 TB/s |
FP64 Tensor Core | 33.5 TFLOPS | 33.5 TFLOPS |
| FP32 | 67 TFLOPS | 67 TFLOPS |
TF32 Tensor Core | 989 TFLOPS | 989 TFLOPS |
FP16 Tensor Core | 1,979 TFLOPS | 1,979 TFLOPS |
FP8 Tensor Core | 3,958 TFLOPS | 3,958 TFLOPS |
INT8 Tensor Core | 3,958 TOPS | 3,958 TOPS |
Decoders | 7 NVDEC, 7 NVJPEG | 7 NVDEC, 7 NVJPEG |
L2 Cache | 50 MB | 50 MB |
Max. Thermal Design Power | Up to 700 W | Up to 1000 W |
Multi-Instance GPUs | Up to 7 MIGs @ 10GB each | Up to 7 MIGs @ 18GB each |
Form Factor | SXM | SXM |
Interconnect | PCIe 5.0 x16 | PCIe 5.0 x16 |
Ultimately, choosing the right GPU largely depends on your workload demands and performance priorities.
Use Cases: Which GPU Should You Choose?
While both the H100 and H200 excel in AI and HPC environments, they serve slightly different needs.
You should consider the H100 if you prefer:
- A proven, high-performance GPU for training medium to large models and handling intensive AI or HPC workloads.
- Use cases involving compute-bound workloads, where total memory capacity is not as critical.
- A time-tested solution already in widespread production use, balancing performance with lower power and cost.
Whereas the H200 may be a better fit if you need:
- Greater memory capacity and bandwidth for running even larger models, handling memory-bound workloads, or scaling LLM inference on the enterprise level.
- Higher throughput, especially for tasks involving extended context windows, multi-modal AI, or very large batch sizes.
- A forward-looking upgrade path with improved energy efficiency and lower TCO, thanks to higher performance per watt.
------------------------------
At Vast.ai, we understand that choosing a GPU isn't only about specs. Often, the decision comes down to access and affordability, as well – especially when we're talking about some of the most powerful and expensive GPUs in existence. (Speaking of, check out our previous posts comparing the H100 vs. A100, and the H100 vs. L40S.)
That's why our cloud GPU rental platform is built to offer high-performance compute at a fraction of the typical cost. Vast gives you flexible, cost-effective access to H100s, H200s, and more.
With options for on-demand pricing and budget-friendly spot instances, you can scale up as needed without overspending. On average, Vast users save 5- 6X on GPU compute compared to traditional cloud providers.
Explore our platform today and get the power you need, when you need it – with no upfront investment required.


