Running RolmOCR on Vast

RolmOCR from Reducto is a powerful, open-source document OCR solution that delivers superior performance while requiring fewer resources than comparable models. Compared to its predecessor, allenai/olmOCR-7B-0225-preview, this new model is built on a better base model, Qwen2.5-VL-7B instead of Qwen2.0-VL-7b. This model isn't trained to take in metadata information and with some 15% rotation of the documents, which enables it to be more flexible under different conditions. Overall, it excels at OCR on PDF's, documents, forms, and invoices. Because it is open source, companies can build on top of this model for their own proprietary pipelines while not sending data to other providers or model hosting services.
Vast.ai offers a GPU marketplace where you can rent compute power at lower costs than major cloud providers, with the flexibility to select specific hardware configurations optimized for specific models and GPU RAM needs, while keeping all of your company's data private.
In this guide, we'll demonstrate how to extract structured pricing data from invoice images using this new model. To follow along, we also have a notebook version you can find here
Deploying RolmOCR on Vast
Install Vast
First, we'll install and set up the Vast API.
You can get your API key from the Account Page in the Vast Console and set it below in VAST_API_KEY.
pip install vastai==0.2.6
export VAST_API_KEY="" # Your API key here
vastai set api-key $VAST_API_KEY
Search for an Instance
Next, we'll search for an instance to host the model. While reducto/RolmOCR requires at least 16GB VRAM, selecting an instance with 60GB VRAM will accommodate larger documents and enable a wider context window.
vastai search offers "compute_cap >= 750 \
geolocation=US \
gpu_ram >= 60 \
num_gpus = 1 \
static_ip = true \
direct_port_count >= 1 \
verified = true \
disk_space >= 80 \
rentable = true"
Deploy the Instance
Using the instance ID from the search, deploy the model to the instance.
Note: we set VLLM_USE_V1=1 to use the v1 engine for vLLM, which reducto/RolmOCR requires.
export INSTANCE_ID= # insert instance ID here
vastai create instance $INSTANCE_ID --image vllm/vllm-openai:latest --env '-p 8000:8000 -e VLLM_USE_V1=1' --disk 80 --args --model reducto/RolmOCR
Using the OpenAI API to Call reducto/RolmOCR
Download Dependencies
While waiting for the instance to finish setting up and starting to serve the model, we'll install the required Python packages locally.
pip install --upgrade openai datasets pydantic
Download Sample Invoice Data
Now, we'll use the datasets library to load a subset of invoice data from the katanaml-org/invoices-donut-data-v1 dataset on Hugging Face. This dataset contains 500 annotated invoice images with structured metadata for training document extraction models.
from datasets import load_dataset
# Stream the dataset
streamed_dataset = load_dataset("katanaml-org/invoices-donut-data-v1", split="train", streaming=True)
# Take the first 3 samples
subset = list(streamed_dataset.take(3))
Next, we'll create an encode_pil_image function to convert images from the dataset into a base64 encoded string format suitable for the OpenAI API.
import base64
import io
from PIL import Image
def encode_pil_image(pil_image):
# Resize image while maintaining aspect ratio
max_size = 1024 # Maximum dimension
ratio = min(max_size / pil_image.width, max_size / pil_image.height)
new_size = (int(pil_image.width * ratio), int(pil_image.height * ratio))
resized_image = pil_image.resize(new_size, Image.Resampling.LANCZOS)
# Convert to bytes with JPEG format and reduced quality for smaller size
img_byte_arr = io.BytesIO()
resized_image.save(img_byte_arr, format='JPEG', quality=85)
img_byte_arr = img_byte_arr.getvalue()
return base64.b64encode(img_byte_arr).decode("utf-8")
Enforcing Structured Data Extraction
We'll create an Invoice Pydantic model for use to store the invoice number and the amount.
from pydantic import BaseModel
class Invoice(BaseModel):
invoice_number: str
invoice_amount: str
json_schema = Invoice.model_json_schema()
Configuring the API Client
Here we're creating a function to interface with the RolmOCR endpoint via the OpenAI API.
Set your instance's IP address and port from the Instances tab of the Vast AI Console.
You can see that we're leveraging the json schema fromt he above Invoice Model to pull have our model generate structured data.
from openai import OpenAI
VAST_IP_ADDRESS = "" # Insert your instance IP address
VAST_PORT = "" # Insert your instance port
base_url = f"http://{VAST_IP_ADDRESS}:{VAST_PORT}/v1"
client = OpenAI(api_key="", base_url=base_url)
model = "reducto/RolmOCR"
def ocr_page_with_rolm(img_base64):
response = client.chat.completions.create(
model=model,
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{img_base64}"},
},
{
"type": "text",
"text": "Return the invoice number and total amount for each invoice as a json: {invoice_number : str, invoice_amount: str}",
},
],
}
],
extra_body={"guided_json": json_schema},
temperature=0.2,
max_tokens=500
)
return response.choices[0].message.content
Extract and Display Invoice Data
Iterate over the sample subset of invoices, display the image, extract the invoice number and amount with RolmOCR, and compare the extracted data to the ground truth.
import matplotlib.pyplot as plt
import json
invoices = []
ground_truth = []
for sample in subset:
# Display invoice image
plt.figure(figsize=(10, 14))
plt.imshow(sample['image'])
plt.axis('off')
plt.show()
# Encode and process with OCR
img_base64 = encode_pil_image(sample['image'])
result = ocr_page_with_rolm(img_base64)
result_dict = json.loads(result)
invoices.append(result_dict)
# Extract ground truth fields
ground_truth_i = json.loads(sample["ground_truth"])
ground_truth_dict = {
"invoice_number": ground_truth_i["gt_parse"]["header"]["invoice_no"],
"invoice_amount": ground_truth_i["gt_parse"]["summary"]["total_gross_worth"]
}
ground_truth.append(ground_truth_dict)
print("Ground Truth")
print(ground_truth_dict)
print("Extracted Info")
print(result_dict)
Example Outputs
Invoice 1
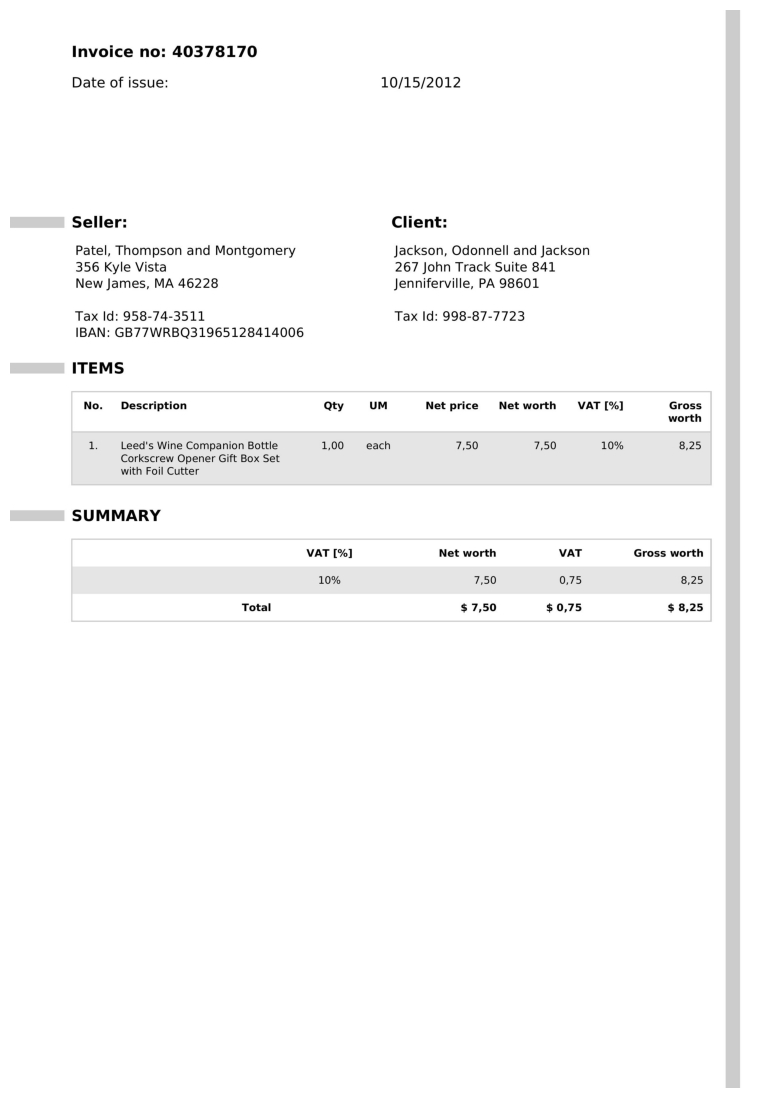
Ground Truth
{'invoice_number': '40378170', 'invoice_amount': '$8,25'}
Extracted Info
{'invoice_number': '40378170', 'invoice_amount': '$8.25'}
Invoice 2
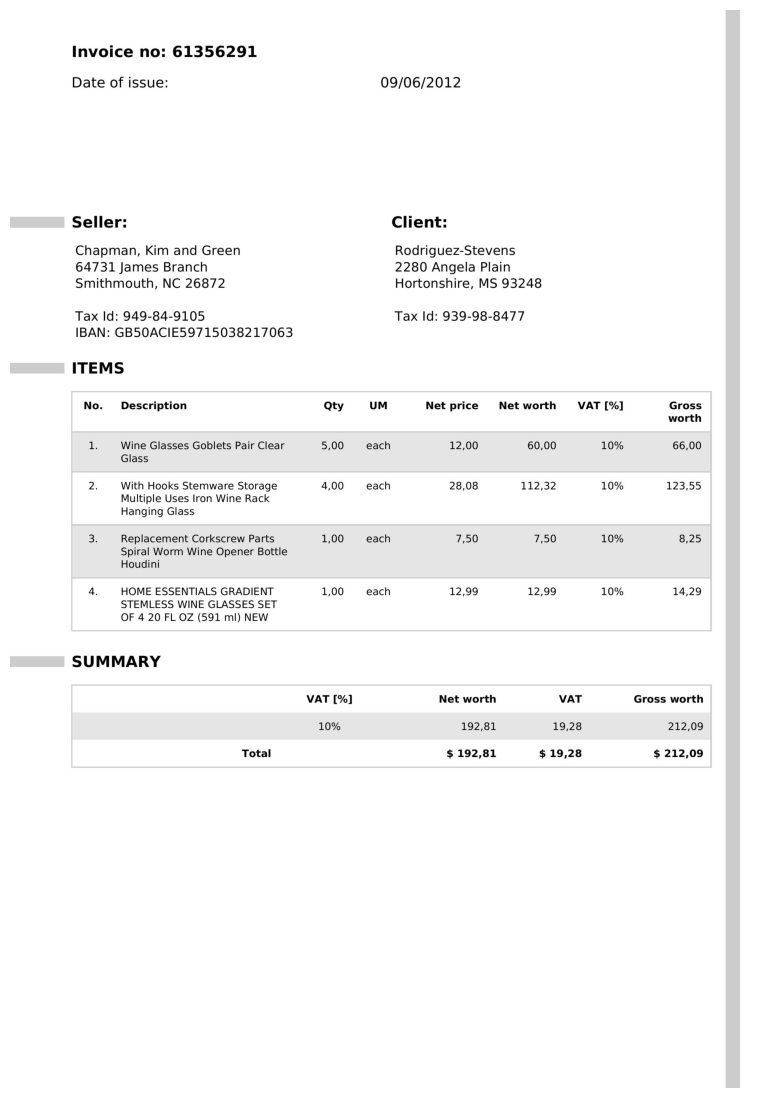
Ground Truth
{'invoice_number': '61356291', 'invoice_amount': '$ 212,09'}
Extracted Info
{'invoice_number': '61356291', 'invoice_amount': '$212.09'}
Invoice 3

Ground Truth
{'invoice_number': '49565075', 'invoice_amount': '$96,73'}
Extracted Info
{'invoice_number': '49565075', 'invoice_amount': '$96,73'}
As observed, the output from reducto/RolmOCR closely matches the expected ground truth, demonstrating its accuracy in extracting key invoice information. The differences between the extracted and ground truth in these cases is around commas versus decimal points, which can be easily solved for with simple downstream methods.
Conclusion
In this walkthrough, we demonstrated how to deploy and use RolmOCR on Vast to extract structured data from invoice images efficiently.
RolmOCR delivers high accuracy for critical fields such as invoice numbers and amounts, while staying more robust with image-based proxessing and reduced RAM usage. When combined with Vast.ai's flexible and cost-effective GPU marketplace, this forms a powerful solution for scalable, privacy-focused document processing workflows.
This approach can be extended to extract a wide range of structured data from diverse document formats, unlocking advanced automation and insights for businesses of all sizes.


