Serving vLLM Embeddings on Vast.ai

Serving vLLM Embeddings on Vast.ai
Background:
vLLM is a developer-friendly framework for serving large language models. It is very fast and focused on high throughput serving multiple simultaneous calls for production use cases. vLLM is now more flexible than ever as it also supports embedding models. This brings vLLM's dynamic batching and Paged Attention to embedding models for much faster throughput, all from the docker image that developers are used to.
This guide will show you how to setup vLLM to serve embedding models on Vast.
Setup and Querying
First, we setup our environment and vast api key
pip install --upgrade vastai
Once you create your account, you can go here to find your API Key.
vastai set api-key <Your-API-Key-Here>
To serve an embedding model, we'll want a machine with a static IP address + ports to forward. We only will need a single GPU, which can have a small amount of RAM since embedding models are small. We'll prefer a modern GPU so we will add a filter for a compute cap of more than 800.
vastai search offers 'compute_cap >= 800 gpu_ram >= 24 num_gpus = 1 static_ip=true direct_port_count > 1 cuda_vers >= 12.4'
Deploying the Image:
The easiest way to deploy this instance is to use the command line. Copy and Paste a specific instance id you choose from the list above into instance-id below.
Hosting a Single Embedding Model:
For now, we'll host just one embedding model.
The easiest way to deploy a single model on this instance is to use the command line. Copy and Paste a specific instance id you choose from the list above into instance-id below.
We particularly need v2 so that we use the correct version of the api, --port 8000 so it serves on the correct model, and --model-id intfloat/e5-mistral-7b-instruct to serve the correct model.
vastai create instance <instance-id> --image vllm/vllm-openai:latest --env '-p 8000:8000' --disk 40 --args --model intfloat/e5-mistral-7b-instruct
Connecting and Testing:
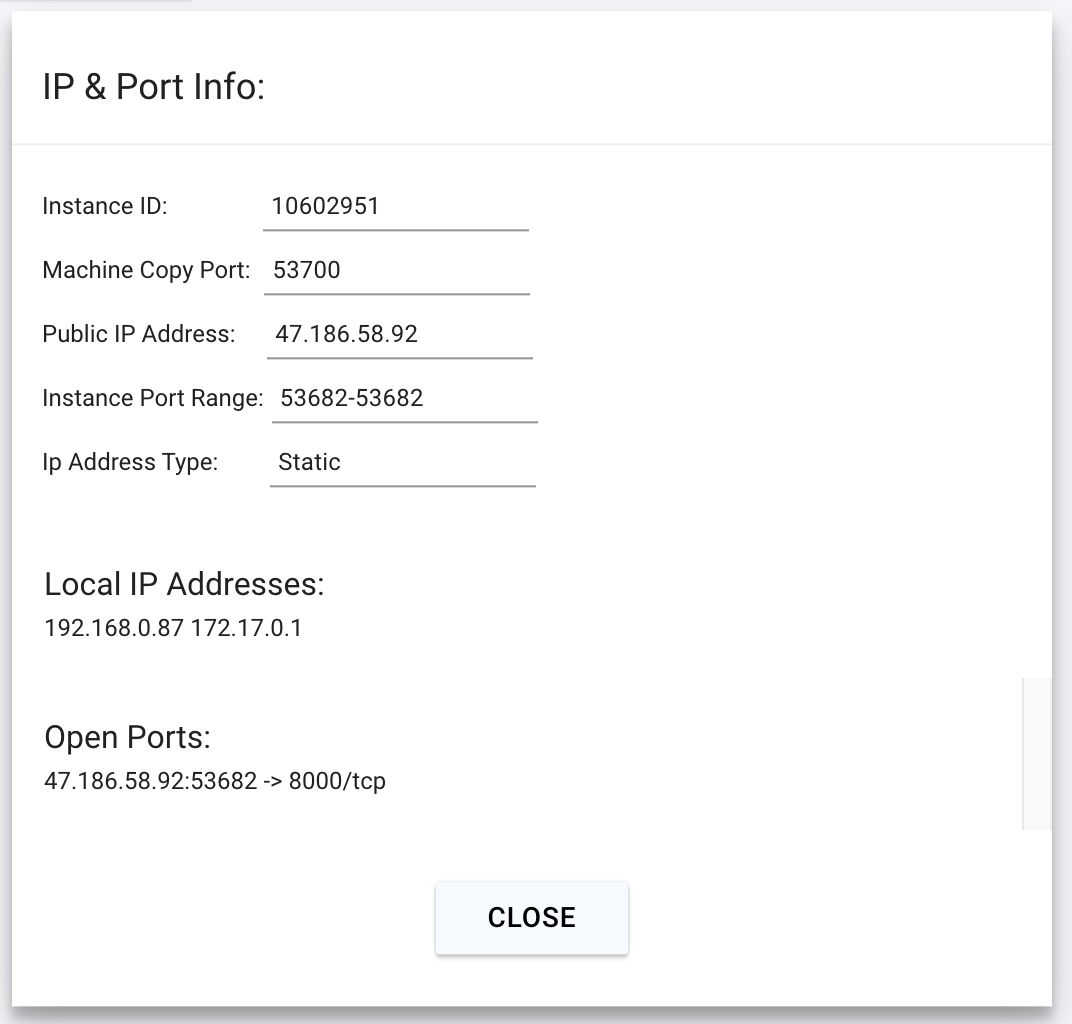
To connect to your instance, we'll first need to get the IP address and port number. Once your instance is done setting up, you should see something like this:

Click on the highlighted button to see the IP address and correct port for our requests.
Connecting with the python requests library
import requests
headers = {
'Content-Type': 'application/json',
}
json_data = {
'model': 'intfloat/e5-mistral-7b-instruct',
"input": ["San francisco is a"],
}
response = requests.post('http://<Instance-IP-Address>:<Port>/v1/embeddings', headers=headers, json=json_data)
print(response.content)
Connecting with the OpenAI SDK
The OpenAI SDK also allows for generating embeddings. We can use it as well with the following code.
pip install openai
We will copy over the IP address and the port into the cell below.
from openai import OpenAI
# Modify OpenAI's API key and API base to use Infinity's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://<Instance-IP-Address>:<Port>/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
model = "intfloat/e5-mistral-7b-instruct"
embeddings = client.embeddings.create(model=model, input="San francisco is a").data[0].embedding
print("Embeddings:")
print(embeddings)
Now we can integrate our embedding server into apps that use the OpenAI SDK.
Next Steps:
Embeddings are an important part of GenAI applications along with running inference of Generative Models. Now with vLLM, you can run them with the same docker image on Vast for ultimate flexibility.


